
By Gennady Krizhevsky
Version 1.0.8
Table of Contents
| ODAL Persistence Framework |
| Summary |
| Preface |
| Motivation |
| Some thoughts on intrusiveness |
| ODAL approach |
| First ODAL Application |
| How To Write Maintainable Applications |
| Basic Ideas |
| High Level Architecture |
| Quick Guide To ODAL |
| ODAL Configuration And Descriptors Format |
| What Is SDL? |
| Install ODAL |
| Generate Basic Persistent Object Descriptors |
| Generate Basic Persistent Objects |
| Create Composite Persistent Objects Descriptor (Optional) |
| Generate Composite Persistent Objects (Optional) |
| Generate Domain Objects and Mapper (Optional) |
| Create DAO Classes (Model 1) |
| Create DAO Classes (Model 2) |
| Instantiate Persistency |
| Put It All Together |
| Using Stand-Alone DataSource |
| Advanced Features Guide |
| Persistent Objects |
| Composite Persistent Objects |
| Enabling Compound Features |
| Enabling Complex Features. Object Trees |
| Many-To-Many Relationships |
| Circular And Bi-Directional Dependencies |
| Combining Compound And Complex Features |
| Other Types Of Persistent Objects |
| Object Serialization |
| Transactions |
| Transaction Listeners |
| Joining Transaction Managers |
| JTA Transactions |
| Primitive Transaction Manager |
| Working With Persistency |
| Retrieving Persistent Objects |
| Loading Persistent Object |
| Query-By-Example |
| Queries |
| Enhancing Query-By-Example |
| Query With Joins |
| Query Returning Data From Multiple Tables |
| Sub-Queries |
| Union Queries |
| Lazy Object Loading |
| Transforming Query Results While Retrieving |
| Query Trees |
| Query Returning Single Value |
| Count And Exists Queries |
| Paginated Queries |
| Query Serialization |
| Query Context |
| Inserting Persistent Objects |
| Pipe Insert |
| Updating Basic Persistent Objects |
| Updating Composite Persistent Objects With Compound Features |
| Updating Composite Persistent Objects With Complex Features |
| More Complex Updates |
| Deleting Persistent Objects |
| Delete-By-Example |
| Modify Queries |
| Pessimistic Locks |
| Optimistic Locks |
| Batch Modify Mode |
| Raw Query Approach |
| Ad-Hoc Modify Statements |
| Pipes |
| Understanding ODAL Data Types |
| Creating Custom Type Handler |
| Creating Custom Column Types |
| Binary Types |
| Key Generators |
| Rule API |
| Generating Persistent Objects From Ad-Hoc Queries |
| Executing Stored Procedures |
| Generating Persistent Objects From Calls |
| Object Caching |
| Persistency Cache Factory |
| Multi-index Cache Factory |
| Cache Integration With ODAL |
| Caching Query Results |
| Query Retrieving Sparsely Populated Objects |
| Oracle SQL Loader Persistency |
| Enabling Logging |
| Using Mapping Persistency (Model 2 Approach) |
| Select Queries With Model 2 |
| Insert And Delete |
| Update |
| Ad-hoc Queries |
| Mapper |
| Code Generating Tools |
| SQL Command Line Tool |
| Examples |
| Integration |
| Terracotta Cache Clustering |
| Spring Framework |
ODAL stands for Objective Database Abstraction Layer. It is a framework to communicate with a persistent storage. It is simple and open to developer since we strongly believe that developer is an intelligent link when it comes to building business applications. ODAL heavily relies on usage of interfaces to shield the developers from the complexities of the framework and to allow for development of plug-ins. ODAL is an ORM framework since it can map relational database tables to application objects. ODAL also supports features usually associated with ORM frameworks such as “lazy” instantiation, ability to retrieve object graphs and to properly express “table inheritance” in terms of Java classes.
Major priorities while developing ODAL were set to maintainability, simplicity, flexibility and performance. Exactly in that order.
Rephrasing Mark Twain, one can say: writing a database access layer is easy, that's why we have so many of them. In reality, it reflects complexity of the problem and the fact that there is no solution that ultimately closes it.
What is different about ODAL from the majority of the similar frameworks on the market? Several things.
As we already said, it focuses on maintainability since we strongly believe in the applications afterlife. It is developed with understanding that modern application is a complex beast and there is a need for business-like transactions as well as batch procedures, report-like ad-hoc queries and so on. It does not use any type of metadata descriptors at runtime. It has minimal dependencies on other libraries. In fact, all the dependencies at runtime are optional except for the JDBC drivers. It does not use Java reflection API. It has minimal overhead as compared to regular JDBC when executing database calls (do not trust those results showing ORM code executing faster than JDBC – they are either using cached ORM objects or non-prepared JDBC statements). It is not “too smart”, meaning it does what it says. For example, if you say “give me object from the database”, it will go to the database to get the object, caching, even though integrated, is done externally, dynamically controllable at runtime. And finally, it comes with the methodology which will be explained later.
To efficiently work with ODAL you have to use the generated objects and extend them if necessary. ODAL generated persistent objects are Java Beans but rather smart ones. They also contain minimum utility methods and they do not save or retrieve themselves from the database.
Generated objects remember their initial state. So you can, for example, select them in one thread and update in another without reloading them from the database if you deem it appropriate.
When dealing with real life business application, J2EE or not, it is commonly accepted that we have to deal with Domain Objects. Domain Objects represent your business or Domain Model. When communicating with external systems or components that know nothing about your Domain you may need another set of objects – so called Data Transfer Objects. Depending on structure of the database that may or may not reflect you Domain Model, you may also need the 3rd set of objects – Persistent Objects, the ones that can be persisted using some persistence framework. For some applications all 3 sets may coincide. For more complicated ones you may need all 3 of them. Interesting that in ORM world the 3rd set of objects is usually omitted since it is assumed that you can map the Domain Objects directly to the database. In reality, sometimes it is true, sometimes it is not. Occasionally, you will find that your database was designed to keep generic kind of objects and has very little to do with the Domain Model.
ODAL is build with this simple fact in mind and is concentrated on the Persistent Objects that, as we said, may or may not coincide with the Domain Model. Of course, we assumed that we do not use plain JDBC since it is still much easier to write converters between Java objects than to clutter application with plain JDBC code.
Nowadays great popularity gained so-called POJO based approach to designing persistence frameworks. POJOs are Plain Old Java Objects – the ones that do not inherit to any specific class or implement any framework dependent interface. So you define your Domain Model objects, map them to database tables and persist them. This is called a non-intrusive approach. It is quite nice and nobody in sound mind would argue with that. However, when it comes to implementing this approach, let us say, in Java, it is usually done through byte code manipulation, tons of XML or the latest invention – annotation mappings that are kept right in the Domain Objects (DOs).
In our mind byte code modification (or runtime code generation, for that matter, meaning usually that your objects get replaced by some other ones), and annotations kept in DOs are not really compatible with the non-intrusiveness or POJO, for that matter, paradigm. Byte code manipulation also complicates debugging since your source code does match the compiled one.
It is worth to mention that byte code manipulation became so fashionable that probably every 9 of 10 new open source Java projects are based on it. The danger is that if you combine couple of such frameworks in the same project you may end up with all kinds of mysterious problems that will be hard to discover.
With ODAL we always build our Persistent Objects (POs) first – they all inherit to a common parent. After that if the database reflects our domain model, we have 2 alternatives – either to derive the DOs from the Persistent ones or to build a separate set of DOs that in this case can be POJOs. If the database does not reflect our business we cannot derive the DOs from the Persistent Objects and we have to build them separately.
We generate our Basic Persistent Objects (the ones that map to the database tables) out of the database, create composite objects (see below) out of the first ones having all the structures predefined before the application run time. That allows ODAL to perform all the persistent operations without any byte code modification or even use of the reflection API (at least when dealing with POs). This approach brings more control, “hard ground”, if you will, to the application – nothing is created out of “thin air”. You can always review code before it gets executed, and many problems can be discovered during compilation. One more thing to consider that even though reflection does not impose a severe penalty anymore, as it was with earlier versions of Java, for some applications the overhead can be considerable. Later on, we will show example persistence that saves objects to sqlLoader files instead of the database. In which case, otherwise small contributors to CPU time become conspicuous.
Any framework endorses certain things and restricts others. This is a positive thing when the methodology is right. ODAL as a framework is not an exception. For example, ODAL consistently prefers Java code to XML, other descriptors or the annotations, for that matter, at runtime. At runtime everything that can be defined or precompiled – should be. It is some kind of strict typing, if you like. We believe that this approach delivers more maintainable code. This includes, by the way, SQL queries. If you want to create an SQL statement, you should not do it as just a string. Why? Because if you change the database even a little, your queries will start failing at runtime. The endorsed approach is to use generated column constants together with Query API, described later. In that case, if you change the database and re-run your code generating scripts the worst thing that can happen - the application will not compile.
Pleasant consequence of ODAL's “precompile-what-you-can” approach is very short startup time. It may not seem extremely important but when you will have to run hundreds of functional tests all of which initializing persistence framework you will learn to appreciate that.
If the POs closely match the Domain Model we can either inherit our DOs from the corresponding POs (see Model 1 approach) or to build a separate Domain Object set. If we choose the latter, and the database reflects our Domain Model, we generate a separate set DOs (POJO beans) the the default mapper between POs (see Model 2 approach).
Martin Fowler in his book “Patterns of Enterprise Application Architecture” mentions several database abstraction layer design patterns that are appropriate depending on size of the application. The problem in real world that the application may start as a small or medium one and over time grow into a very large. Usually, this switch would require a big refactoring including the persistence layer replacement. ODAL allows you to shift from “Transaction Script” approach to “Active Record” to “ORM” like one smoothly.
Words are words but as they say: “Show me the money!”.
Here you are. The 1st application with ODAL. Not really a “HelloWorld” but - “HelloOdal”:
package com.completex.objective.persistency.examples.ex001;
import com.completex.objective.components.log.Log;
import com.completex.objective.components.persistency.PersistentObject;
import com.completex.objective.components.persistency.core.adapter.DefaultPersistencyAdapter;
import com.completex.objective.components.persistency.transact.Transaction;
import java.io.FileInputStream;
import java.io.IOException;
import java.sql.SQLException;
import java.util.Properties;
public class HelloOdal {
public static String configPath = "examples/src/config/hsql.properties";
public static void main(String[] args) throws IOException, SQLException {
if (args.length > 0) {
configPath = args[0];
}
Properties properties = new Properties();
properties.load(new FileInputStream(configPath));
DefaultPersistencyAdapter persistency = new DefaultPersistencyAdapter(properties);
Transaction transaction = persistency.getTransactionManager().begin();
persistency.executeUpdate("CREATE TABLE EX_HELLO_TABLE (NAME VARCHAR(30))");
persistency.executeUpdate("INSERT INTO EX_HELLO_TABLE VALUES ('Hello ODAL!')");
PersistentObject po = (PersistentObject) persistency.
selectFirst(persistency.getQueryFactory().newQuery("SELECT * FROM EX_HELLO_TABLE"));
printResult(po);
persistency.executeUpdate("DROP TABLE EX_HELLO_TABLE");
persistency.getTransactionManager().commit(transaction);
}
private static void printResult(PersistentObject po) {
System.out.println(" Congratulations: your 1st data retrieved from the database: by index: "
+ po.record().getString(0));
System.out.println(" Congratulations: your 1st data retrieved from the database: by name : "
+ po.record().getString("NAME"));
}
}
What did we just do? We created a table, inserted some data into it and retrieved it into generic PersistentObject. As you can probably guess from the code, PersistentObject contains a Record from which the values can be accessed either by index or by name.
This is an example of the “Transaction Script” approach. All the configuration – database connectivity properties.
Good applications live longer. That is a fact, and the emphasis here is on live. That means that the applications are under steady development even at the stage of maintenance. In a way, maintenance is the most important part of the application life since it is the longest one. One of the features of this period is that the development during it is trickier and riskier since the application is already in production.
It is interesting to observe the evolution of ORM frameworks in retrospect. They were created with a very noble idea in mind – to hide the complexities of databases from application developers. The developers would map their application objects to database tables, using some kind of XML descriptor, the framework would use it to do the operations with the object graphs, which, in turn, would be translated into the database operations. No SQL whatsoever. The reasoning was simple - 95% of code in the server application can be dealt with this way. We would argue that 95 is a bit high but, anyway, here comes the notorious 80/20 (or, in this case, 95/5) rule. People realize that it is hard to live without SQL. So, here the ORM frameworks lost their purity, they introduced kind of SQL. In the beginning, it was just a dialect of “object query language”. Soon though it became obvious that it is not enough, and they started supporting “native queries” also.
ORM XML descriptors evolved over time also. As any ORM framework documentation would claim, it is not hard to write the XML descriptor mapping fields to columns and linking the objects into the object graphs. And, it is really not ... if you have, let's say, 5 tables with 4 columns each. But once you have 100, 200 or, as some larger applications do, 1000 and more tables with 20 or more columns each, it gets challenging to do even through a visual tool. No wonder that nobody liked it. “It is not a problem”, said ORM developers, and introduced code generating tools. The tool would generate the XML descriptors and the objects out of the database since, as we mentioned before, the databases, especially the big ones, are rarely created without PDM tools and as a rule come to existence before the application based on it. This, by the way, should not be surprising since the databases are part of infrastructure, architecture wise, and the applications are part of processes. Given that you can build any number of processes based on the same infrastructure, the infrastructure comes first. Generating XML descriptors and the objects was probably the only logical and viable thing to do for a medium-to-large scale applications. However, in a way, it defied the main idea of the “object-relational mapping” since if the objects are generated out of a database, their structure is pretty much defined by the structure of the database. Code generation is not an integral element of ORM ideology. It came rather as a patch to it. And it did not really solve the XML descriptors maintainability problem. You can generate your descriptors and the objects, however, once you touched them – they are yours. And it is worth to note that supporting tons of XML is much harder than supporting tons of Java code. Now, imagine that you have another ton of either externally or internally kept SQL or OQL strings that reference that thousands of fields or columns and what happens if you decide to make a change in your database or object structure, for that matter. Reality, as anyone knows, is even worse as you would probably have several groups of developers modifying the database simultaneously.
What about the annotations based mappings which seem to be the recent direction that ORM mainstream has taken? In our opinion, it makes the situation even worse since not solving the maintainability problem it introduces coupling with the framework which XML based approach did not have.
Database centered application is different from a self-sufficient one in at least one but very important aspect – your code resides in 2 different places. Any developer knows how hard is to maintain redundant code synchronous even within the system written in the same language. It is especially difficult in case of 2 different not even languages – tools. To do it efficiently, one has to use some methodology. Let's say we do the change in one place and then propagate it to another using some automation. Being more specific, we modify the database first, to be consistent with what we said before about the infrastructure, and after that we regenerate our application artifacts. With such an approach, the code generation becomes not just an optional add-on but an integral part of the methodology. We admit that not everything can be and should be generated out of the database and we will discuss it later. Here is another thing, if we regenerate the descriptors and the objects every time the database change happens, how does it combine with the manual work that, as we admitted, may take place? We do it by “separating concerns”. We split the descriptors and objects into ones that cannot be modified by hand and those that can be.
It also should be mentioned that going another way – generating database scripts or directly modifying the database from the Domain Model – is much harder. One of the reasons is that databases may contains a lot of parameters that simply unknown in the Domain world, like storages, tablespaces, and so on. In addition, the way from the database to Java, for instance, is better defined that the way back. For example, if you have Clob or varchar2 in Oracle you can always map it to a String, but if you have String you cannot know what Oracle type to use for it because if String contains more than 4000 characters (and this number may be actually version dependent) it has to be mapped to a Clob. Of course, we can always map Strings to Clobs paying a big price in performance. One more thing to keep in mind – databases live by their own rules and determining what data element go to which table involves performance considerations. Disregarding the latter is not an option since database in the vast majority of cases is the performance bottleneck. Ideally the Domain Model design should be always performed with the database design in mind.
One of the sources of poor maintainability – SQL stored as strings inside the code or externally in the files. From the experience, SQL stored in files is good for testing but not for a production application. The alternative would be: wherever it is possible avoid using SQL at all, wherever it is not – generate symbolic constants corresponding to field names and use them in code to produce the SQL instead of strings or external files in cases when SQL is necessary. Try to modify or drop some field/column names and you will appreciate the advise. If you follow it the worst thing that may happen - your code will not compile, the problem that is much easier to fix than plowing through the strings or files in search of those needing the modification. And the argument that it is “cleaner” to store your SQL in files we are not “buying” since you can always separate you queries using pure Java as well.
Let's talk about simplicity of the application and persistence frameworks. Nobody argues that simple code is better than complex one doing the same job. Sometimes simplicity of the application is mistakenly measured in lines of code. That's true that unnecessary code complicates its readability. At the same time, it is also true that more code in many cases can improve it. Actually, that's kind of obvious. Let's ask ourselves another question. Do we care about internal complexity of a persistence framework we are using? The answer is not that obvious. As long as it does the job why should we? Surprisingly, it can affect us. Sure, the readers are very good programmers, never make mistakes but occasionally, out of curiosity, they can still launch the debugger. Would you be surprised if, say, after loading the object from the database you would find all its fields empty? I know – I would be. And pretty annoyed too. That's exactly what can happen when you use some of the “non-intrusive” ORM frameworks since occasionally they modify the byte code. Now, imagine the situation when you are fixing a critical production bug, launch the debugger and ... . Sometimes, complexity of the framework can expose itself in some other ways - long startup times, for instance. While evaluating the framework it usually does not seem that important. Yes, it takes 2 minutes to start it, so what? It does it only once - on the application launch. And, we would add, on the launches of all your functional tests. Now again, imagine yourself fixing a critical production bug ... . By the way, occasionally, you will find that you have to restart your application server and the startup time is important. Or you write an application that is launched as a cronjob with the time interval compared with the startup time itself.
We should say more about simplicity in its relation to the persistence frameworks. How to keep it simple? One of the ways – is not to use hard to understand features, try to avoid code based on the framework specific behaviour. Here is the example. Some people would say that great advantage of the ORM frameworks is that if you ask it for the same object twice during the transaction you would get the same instance of it. And, some may add, it is called transactability (we realize that this is not a dictionary term – at least not yet – but it is commonly used and means “transaction like behaviour”). It's definitely not transactability but rather an attempt to simulate a “serializable” transaction isolation level. The question is though – would you expect this type of behaviour from the ORM tool? Not necessarily, if you ask the database for the object twice in the same transaction it will just retrieve it twice. Now, some may misuse this knowledge and write code like:
openTransaction();
int id = 1;
f1(id);
Person p = f2(id);
persistency.save(p);
closeTransaction();
private Person f1(int id) {
Person p = persistency.get(id);
p.setName(“John”);
return p;
}
private Person f2(int id) {
Person p = persistency.get(id);
p.setGender(“male”);
return p;
}
If our goal was to update a Person with a new name and gender then the first impression - it's done incorrectly, that only the gender field will be updated. Does the persistence go to the database twice? “No”, the expert would say, “We get the same instance of the Person every time as long as we are in the same transaction”, and will be very satisfied with himself. In our mind though, much better would be code like this:
openTransaction();
int id = 1;
Person p = persistency.get(id);
f1(p);
f2(p);
persistency.save(p);
closeTransaction();
private void f1(Person p) {
p.setName(“John”);
}
private void f2(Person p) {
p.setGender(“male”);
}
It's more intuitive and hence more maintainable. And, by the way, more efficient too.
When the EJB technology first came it promised to solve all the problems. And it solved ... some of them. But ultimately it failed. Proof of it - radically different successive EJB specifications. Why did it fail? The problem was in “do not care” attitude it started with. For example, “We do not care that it takes forever to run an EJB application – machine power is cheap and getting cheaper by a minute”. Or, “After this technology comes, companies will not have to care about the application developers anymore - with the architecture in place a monkey can to the job”. It was the “magic bullet” approach. As we know, it did not work, and developers are still around, and the good ones are still in demand. So, was the architecture wrong? Then why a great team of EJB architects did not find the right one? I hate talking banalities, but probably because there is no such thing that “kills'em all”. What to do then? Okay, maybe the right way is to create a set of technologies that intelligent architects and developers would combine and use to fit their needs. These technologies should be specialized and possibly simple. Actually, this is the tendency that takes place in the open source community.
Thus, the concept “simplicity is a virtue” applies to frameworks also. Not always this philosophy wins, though. Take, for example, object caching. Some ORM frameworks make cache (so called secondary one) internal to the framework. Should it be? There are several reasons why it should not. First of all, being internal it usually cannot sufficiently cover all possible caching scenarios. For example, in some cases one may need caching by surrogate key, and the natural one, and maybe, some other keys too. After that one may need to synchronize population and invalidation of those caches. Also sometimes on load of the class one may need to cache only specific instances to minimize the cache size. Moreover, there is another, non-obvious, side effect of internal cache use: it makes it look like no matter what silly things you do in your code, the framework will compensate, which is clearly not true. It therefore implicitly endorses sloppy DOs design, inconsistent caching policies, which, in turn, lead to potential erratic system behaviour and maintainability problems. The application should be designed in such a way that it is efficient enough even without caching. Caching should come as an optional add-on, and not as a must-to-have compensation device for the application or the framework (which is often the case) deficiencies. Keeping in mind that the ORM framework will likely be using external cache implementation anyway and that we target intelligent developers, it would be better to give them 2 frameworks and allow to combine it by themselves. Occasionally, one would need to make ORM and caching work together. Example is a distributed cache when you have to invalidate the values on commit (more precisely – after commit). For that purpose, the persistence framework should provide proper means of communication - transaction events listeners, for instance, letting the developers to hook up the 2 frameworks when necessary. Even though external caching will likely lead to more lines of code, it will also likely make the application better controlled and more maintainable.
ODAL is called Objective for a reason - it is based on specialized objects which stem from the PersistentObject class. As we saw in HelloOdal example, PersistentObject can be used directly. However, the normal way would be to create strictly typed Java Beans that inherit from the PersistentObject class. One of the main ODAL goals was to design an easy and flexible way to create and modify those objects which are deemed a foundation of an application success. And crucial idea here is in separating routine work from an intelligent one, relatively static components from frequently modified ones, and dividing the process into stages that allow developers input. It is like a “separation of concerns” pattern but applied in both spacial and time dimensions.
To achieve this goal the are separated into two essentially different types: basic and the composite (complex/compound) ones. The basic are those mapped one-to-one to database tables. The composite ones are compositions of the basic persistent objects.
This simple separation allows for gradual evolution of your application complexity and provides for effective use of code generation technique.
Generation of basic POs is done it in two steps. The first step is to generate persistent descriptors for the basic persistent objects. These descriptors always go in pairs – one “internal” and one “external”. The internal descriptor contains database metadata and it is never modified by hand. The external one contains metadata that may be modified by hand if necessary – it contains column types, foreign keys, value generators metadata, column aliases or future Java object field names. Some entries in both descriptors may overlap in which case the external descriptor ones take precedence. Modified entries of the external descriptor do not get overwritten in subsequent re-generations except for the cases when the entire column gets deleted from the database. The second step is to generate basic based on the descriptors we just described.
After the basic are generated we can optionally aggregate them into groups of composite persistent objects. It can be done either programmatically or through code generation. Generation of composite is also done in two steps. The first one is to write a descriptor that describes how these object relate to each other. This is the most intelligent step. It cannot be truly automated and should be done manually. The second step is a trivial one in which we generate our composite based on the descriptor.
As you can see, the process of persistent object generation involves several stages and creates several artifacts. After each step developers can interfere with their input. That gives them enough control over the process. Also, this mechanism allows to automatically propagate database changes to the code.
Working with generated is one of the central ideas of ODAL. The POs contain metadata about the tables they are mapped to. That allows using them to build queries without writing SQL. On another hand, do no save or retrieve themselves which provides for better reusability.
If you want to modify the generated to add your own methods you should either inherit from the generated POs or generate DOs and PO/DO mapper which will be discussed later.
ODAL creates an abstraction layer between an application and a persistent storage. A high level view of the architecture looks like that

The application uses ODAL and its generated artifacts to communicate with persistent storage.
Persistency is an object that performs all the operations regarding storing and retrieving persistent objects.
TransactionManager is an object closely related to Persistency that manages database and non-database transactions and sessions.
DOs belong to the Application layer but, as we already mentioned, they can be generated and mapped to the corresponding POs.
ODAL is currently using 2 formats for configuration files. One is usual Java properties file format. For more complicated configurations and the descriptors we use SDL (Simple Data Format) format.
SDL format was proposed by Andrew Suprun and presents a convenient alternative to XML. It supports the following data types: maps, lists, strings, numbers, booleans, timestamps and nulls. White spaces are used as token separators unless they are inside strings.
Map syntax: {<key> = <value>}
List syntax: [<value1> <value2> ... <valueN>]
String syntax: “<value>” or <value> if the value contains alphanumeric characters
Number syntax: <value> where value contains digits only
Boolean syntax: TRUE|FALSE
Timestamps syntax: @<yyyy-MM-dd'T'HH:mm:ss>|@<@yyyy-MM-dd>
Null value syntax: NULL
Single line comment syntax: #
SDL format contains much less tag “noise” than XML what makes it more readable. SDL works nicely for configurations and simple resource files where XML looks like an overkill. ODAL has an implementations for SDL reader and SDL writer. To build an SDL structure all you have to do is build a Map/List tree. SDL writer knows how to save it to SDL format. SDL reader, on another hand, reads SDL code into a Map/List tree.
Below is a sample of SDL code:
{
#
# Map:
#
generic={
po_config_path=somfile.sdl
cpx_desc_path=complex_test.sdl
intern_path=gen/src/java/sdl/persistency/oracle/internal_test.sdl
extern_path=gen/src/java/sdl/persistency/oracle/external_test.sdl
generate_interfaces = TRUE
}
#
# String:
#
filter_pattern="TEST_M|TEST_S"
#
# List:
#
values = [“value-1“ “value-2”]
}
Once you downloaded the binary distribution – unpack it. The root directory of the unpacked file structure is your $ODAL_HOME. You can choose to set it in your environment or not. We will refer to it for convenience down the road. Copy your database driver to $ODAL_HOME/lib directory. Note that $ODAL_HOME/lib directory contains a set of Java archives out of which only one – odal.jar – is mandatory at runtime. If you use JTA transactions you have to include also javax_jta-1_1.zip, and if you use commons logging – include commons-logging.jar. Of course, you have to include your database driver to the classpath as well.
Create your $CONFIG directory where you will keep you configuration files – it will likely be under your application directory tree. Copy persistent-descriptor-config.properties file from $ODAL_HOME/config/ref directory to the $CONFIG directory. $ODAL_HOME/config/ref directory contains templates for all the configuration files you may need. Modify the copied file appropriately. The most importantly, uncomment and set the database configurations.
Run
$ODAL_HOME/bin/desc-po.sh $CONFIG/persistent-descriptor-config.properties
command from console (this is UNIX example, there are corresponding commands for Windows if for some inexplicable reason you choose to run one). It will generate 2 descriptors, internal and external, necessary to generate basic persistent objects.
At this point you may choose to modify the external descriptor. The content of the file may look like
{
tables = {
CONTACT = {
tableAlias = CONTACT
tableName = CONTACT
columns = {
CONTACT_ID = {
columnName = CONTACT_ID
columnAlias = CONTACT_ID
dataType = LONG
optimisticLock = FALSE
exclude = FALSE
transformed = FALSE
# keyGenerator = {
# class = com.completex.objective.components.persistency.key.impl.SimpleSequenceKeyGeneratorImpl
# staticAttributes = {
# name = CONTACT_SEQ
# }
# }
CUSTOMER_ID = {
columnName = CUSTOMER_ID
columnAlias = CUSTOMER_ID
dataType = LONG
optimisticLock = FALSE
exclude = FALSE
transformed = FALSE
}
#
# Some columns hes been removed from this sample
# ..............................................
#
}
exclude = FALSE
transformed = FALSE
foreignKeys = {}
naturalKey = {
columnNames = []
naturalKeyFactory = {
# simpleFactoryClassName =
}
}
}
CUSTOMER = {
tableAlias = CUSTOMER
tableName = CUSTOMER
columns = {
........
}
}
}
}
As you can see the external descriptor contains set of table entries. Each entry has a table name as a key. Let us review CONTACT entry in details.
CONTACT – key of the table entry, coincides with the table name.
tableAlias – CONTACT, table alias. By default coincides with the table name. It is used as class or interface name core (it will be transformed according to Java convention with optional prefix and suffix being provided in the configuration file). Can be modified.
tableName – CONTACT, table name, should not be modified and given here for reference purpose only.
columns – columns entries key.
CONTACT_ID – 1st column key, coincides with the 1st column name.
columnName – CONTACT_ID, column name, should not be modified and given here for reference purpose only.
columnAlias – CONTACT_ID, column alias. By default coincides with the column name. It is used as generated Bean field name seed (it is formatted to Java standard). Can be modified. Enclosed in parentheses “(...)” it stays unformatted and gets interpreted as an exact field name (it should be also enclosed in double quotes since otherwise SDL reader does not interpret it correctly and will throw an exception).
dataType – LONG, ODAL column type (see ColumnType in API documentation). Data types are discussed in details later. Can be modified
optimisticLock – FALSE, boolean value indicating if this column is part of optimistic lock key. Can be modified
exclude – FALSE, boolean value indicating if this column should be excluded from the generated Bean fields. It is convenient when several versions of your application share the same development database. If you regenerate the descriptor from the development database that has additional columns you may exclude them without breaking the older production version that does not have them. Can be modified.
transformed – FALSE, systemic flag. Should not be modified.
keyGenerator – key generator entry. Comes as commented out. Uncomment, modify or add it as required (see detailed description below).
class – com.completex.objective.components.persistency.key.impl.SimpleSequenceKeyGeneratorImpl, generator class name (see detailed description below).
staticAttributes – arguments that will be set when initializing generator. See API documentation for attributes that can be set for a specific generator.
name – CONTACT_SEQ, sequence name
CUSTOMER_ID – 2nd column key
......
exclude – FALSE, boolean indicating if the table should be excluded from object generation. Can be modified.
transformed – FALSE, systemic flag. Should not be modified.
foreignKeys – foreign keys entry. If not specified, the one from the internal descriptor file is used. Can be modified. The easiest way to modify it is to start from one copied from the internal descriptor file.
naturalKey – entry describing key that is used in PersistentObject.toKey() method. If not specified or empty the default one is used. It includes all the primary key columns to the key. You can always override PersistentObject.toKey() method and provide your own key specification.
columnNames – [], list of column names used to form the key
naturalKeyFactory – key factory.
simpleFactoryClassName – simple factory class name. Key factory implementation provided by ODAL is "com.completex.objective.components.persistency.key.impl.SimpleNaturalKeyFactoryImpl". For compound consisting of several basic ones the resulting key is formed as a superposition of its entries ones.
What should you modify in an external descriptor? You should uncomment and modify name or class of key generators if you need them. Foreign key entries normally reside in the internal descriptor. However, if there is danger of dropping them in the database you should consider copying the from the internal into the external one. Occasionally, you will find necessary to change the data type of the column. For example, some JDBC drivers will not tell you if this column type can be interpreted as a BLOB putting more generic BINARY type instead. If you know that this database type can be correctly converted to BLOB by the driver you may decide to modify the generated type.
Once modified, the external descriptor column entries are not overwritten in subsequent regenerations. However, if the table or column is deleted from the database it will also be deleted from the external descriptor.
When generating objects, table and column aliases rather than names are used to derive class and field names of the generated classes. If you are not satisfied with default name conversion you can specify alias values enclosed in parentheses “(...)” and they will be interpreted as exact class or field names, respectively.
The tables keys in the external descriptor must match those in the internal one.
Since you cannot have duplicate table entries in the descriptors, in case you need another persistent object generated from the same table, you have to generate an alternative descriptor pair (or copy them from an existing one).
The data types mentioned in descriptor are internally supported ODAL data type. For the complete list of them please refer chapter Understanding ODAL Data Types. You can also create you custom types as it will be shown in the Advanced Features Guide.
You can also define transformer classes that can alias tables or columns, or redefine column type. To do that you have to create a plugin configuration file in SDL format (see persistent-descriptor-plugins-config.sdl template). Below is an example of such a configuration:
{
transform = {
transformers = [
{
class = "com.tools.BooleanModelTransformer" # Required, must be of ModelTransformer type
# config = {} # Optional
}
# NameModelTransformer
{
class = "com.tools.NameModelTransformer" # Required, must be of ModelTransformer type
# config = {} # Optional
}
]
}
}
This configuration file defines two transformers. Following are the sample transformers sources,
public class BooleanModelTransformer extends AbstractModelTransformer implements ModelTransformer {
protected void transformColumn(MetaTable table, MetaColumn column) {
if (column.getColumnName().endsWith("_FLAG")
&& ColumnType.isString(column.getType())
&& column.getColumnSize() == 1) {
if (column.isRequired()) {
column.setType(ColumnType.BOOLEAN_PRIMITIVE);
} else {
column.setType(ColumnType.BOOLEAN);
}
}
}
}
public class NameModelTransformer extends AbstractModelTransformer implements ModelTransformer {
protected void transformColumn(MetaTable table, MetaColumn column) {
if (column.getColumnName().equalsIgnoreCase("CLASS")) {
column.setColumnAlias("CLAZZ");
}
}
}
As you can figure out, the first one changes type of the column to boolean when the column name ends with “_FLAG”, and the second one aliases the columns named “CLASS” to “CLAZZ” to avoid Java object fields called “class” when generating Persistent Objects.
The last thing to do with regards to transformers is to point plugins_config_path property of persistent-descriptor-config.properties to the path of persistent-descriptor-plugins-config.sdl file.
Copy persistent-object-config.sdl file from $ODAL_HOME/config/ref directory to the $CONFIG directory. Modify the copied file appropriately.
Run
$ODAL_HOME/bin/po.sh $CONFIG/persistent-object-config.sdl
command from console. Review the generated classes.
If you need to work with object trees that are mapped to related tables and the tree elements should be retrieved and modified together, you may decide to create composite which are aggregations of the basic ones. Such aggregations represent master-slave relationships of two types – complex and compound. The complex one provides for weaker parts dependencies than the compound one. For example, if you want to implement “lazy loading” or simply get dependency type other than one-to-one then you have to do it though complex object feature. On another hand, if you want your composite to behave more like a single basic persistent object then you have to implement the compound object feature. Composite object, in fact, can have both complex and compound features as it will be shown below. You can create your composite objects descriptor from scratch but the best way is to start from the $ODAL_HOME/config/ref/composite-po-descriptor.sdl template. It contains rather detailed descriptions of the attributes you have to set are aggregations of the basic ones.
Copy composite-po-config.sdl file from $ODAL_HOME/config/ref directory to the $CONFIG directory. Modify the copied file appropriately.
Run
$ODAL_HOME/bin/po-cmp.sh $CONFIG/composite-po-config.sdl
command from console. Review the generated classes.
This step in necessary if you decide that you cannot or simply do not want to inherit from the generated POs.
Copy bean-config.sdl file from $ODAL_HOME/config/ref directory to the $CONFIG directory. Modify the copied file appropriately.
Run
$ODAL_HOME/bin/bean.sh $CONFIG/bean-object.sdl
command from console. Review the generated classes.
Depending on the model you adopted (including choice to work with basic ones or with composites) your DAO classes may look simpler or more complex. Following is an example of DAO class using composite persistent objects,
public class CustomerDAO {
private Persistency persistency;
public CustomerDAO(Persistency persistency) {
this.persistency = persistency;
}
public void setPersistency(Persistency persistency) {
this.persistency = persistency;
}
public void insertCustomer(final Customer customer) throws CustomerException {
try {
persistency.insert(customer);
} catch (OdalPersistencyException e) {
throw new CustomerException(e);
}
}
public void updateCustomer(final Customer customer) throws CustomerException {
try {
persistency.update(customer);
} catch (OdalPersistencyException e) {
throw new CustomerException(e);
}
}
public void deleteCustomer(final CpxCustomer customer) throws CustomerException {
try {
persistency.delete(customer);
} catch (SQLException e) {
throw new CustomerException(e);
}
}
public Customer loadCustomer(final Long customerId) throws CustomerException {
try {
return (Customer) persistency.load(new CpxCustomer(customerId));
} catch (OdalPersistencyException e) {
throw new CustomerException(e);
}
}
/**
* Load all the customers. Utilizes BasicLifeCycleController.convertAfterRetrieve method
* to pre-load otherwise lazily loadable Contact.
*
* @return list of customers
* @throws CustomerException
*/
public List loadAllCustomers() throws CustomerException {
try {
return (List) persistency.select(new CpxCustomer(), new BasicLifeCycleController() {
public Object convertAfterRetrieve(AbstractPersistentObject persistentObject) {
((CpxCustomer) persistentObject).getContact();
return persistentObject;
}
});
} catch (OdalPersistencyException e) {
throw new CustomerException(e);
}
}
}
The CustomerDAO class is taken from $ODAL_HOME/examples/src/java/com/completex/objective/persistency/examples/ex004/app
directory. Below is the class diagram of the ones used by the CustomerDAO. User defined descendants are Customer and Contact classes.
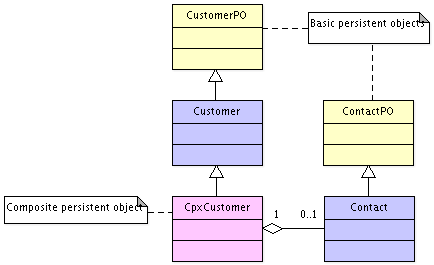
As you can see from the code CustomerDAO has reference to Persistency interface.
When working with the Model 2 you would generate 2 sets of classes – POs and DOs. Below is the example of DAO utilizing the 2nd model,
public class CustomerDAO {
private MappingPersistency persistency;
public CustomerDAO(MappingPersistency persistency) {
this.persistency = persistency;
}
public void setPersistency(MappingPersistency persistency) {
this.persistency = persistency;
}
public void insertCustomer(final CpxCustomer customer) throws CustomerException {
try {
persistency.insert(customer);
} catch (OdalPersistencyException e) {
throw new CustomerException(e);
}
}
public void updateCustomer(final CpxCustomer customer) throws CustomerException {
try {
persistency.update(customer);
} catch (OdalPersistencyException e) {
throw new CustomerException(e);
}
}
public void deleteCustomer(final CpxCustomer customer) throws CustomerException {
try {
persistency.delete(customer);
} catch (SQLException e) {
throw new CustomerException(e);
}
}
public CpxCustomer loadCustomer(final Long customerId) throws CustomerException {
try {
return (CpxCustomer) persistency.load(new CpxCustomerPO(customerId));
} catch (OdalPersistencyException e) {
throw new CustomerException(e);
}
}
/**
* Load all the customers. Utilizes BasicLifeCycleController.convertAfterRetrieve method
* to pre-load otherwise lazily loadable Contact.
*
* @return list of customers
* @throws CustomerException
*/
public List loadAllCustomers() throws CustomerException {
try {
return (List) persistency.select(new CpxCustomerPO(), new BasicLifeCycleController() {
public Object convertAfterRetrieve(AbstractPersistentObject persistentObject) {
((CpxCustomerPO) persistentObject).getContact();
return persistentObject;
}
});
} catch (OdalPersistencyException e) {
throw new CustomerException(e);
}
}
}
This CustomerDAO class is taken from $ODAL_HOME/examples/src/java/com/completex/objective/persistency/examples/ex004a/app
directory. Below is the class diagram of the ones used by the CustomerDAO.

Note that instead of Persistency interface this CustomerDAO class uses MappingPersistency interface.
The 1st example shows how to get Persistency instance using generic approach,
// Instantiate Persistency (1):
DatabasePolicy policy = DatabasePolicy.DEFAULT_ORACLE_POLICY;
DefaultTransactionManagerFactory tmFactory = new DefaultTransactionManagerFactory();
tmFactory.setDataSource(dataSource);
tmFactory.setDatabasePolicy(policy);
TransactionManager transactionManager = tmFactory.newTransactionManager();
DefaultPersistencyFactory pf = new DefaultPersistencyFactory();
pf.setTransactionManagerFactory(tmFactory);
Persistency persistency = pf.newPersistency();
It allows you to use externally supplied datasource and transaction manager.
The simplest way to get Persistency instance is to use DefaultPersistencyAdapter.
// Instantiate Persistency (1):
Persistency persistency = new DefaultPersistencyAdapter(properties);
It instantiates ODAL datasource internally. The properties that can be set in properties parameter are described by PROP_XXX constants of DefaultPersistencyAdapter class (see the API documentation). It is more appropriate though for small rather than enterprise applications.
You can also use alternative DefaultPersistencyAdapter constructor which accepts any externally supplied DataSource,
// Instantiate Persistency (2):
Persistency persistency =
new DefaultPersistencyAdapter(properties, dataSource,
StdErrorLogAdapter.newLogInstance());
If statement cache size is set to 0 the internal prepared statement caching is disabled as it should be in case the caching is done at the driver level or simply undesirable.
If you use model 2 approach you can instantiate MappingPersistency in the following ways.
// Instantiate Persistency (1):
MappingPersistency persistency = new DefaultMappingPersistencyAdapter(properties);
or
// Instantiate Persistency (2):
MappingPersistency persistency = new DefaultMappingPersistencyAdapter(persistency, mapper);
where persistency is instance of Persistency and mapper is instance of com.completex.objective.components.persistency.mapper.Mapper.
Following is an application example using CustomerDAO to create customers,
public void doIt() throws CustomerException {
Transaction transaction = persistency.getTransactionManager().beginUnchecked();
try {
createAllCustomers();
// Commit w/o returning transaction to the pool
transaction.commit();
} finally {
persistency.getTransactionManager().rollbackSilently( transaction );
}
}
private void createAllCustomers(Transaction transaction) throws CustomerException {
try {
......
CpxCustomer customer = createCustomer(“Macrohard”, “www.macrohard.com”);
Contact contact = createContact();
customer.setContact(contact);
customers.add(customer);
customerDAO.insertCustomer(customer);
......
} catch (SQLException e) {
throw new CustomerException(e);
}
}
private CpxCustomer createCustomer(String orgName, String url) {
CpxCustomer customer = new CpxCustomer();
customer.setOrgName(orgName);
customer.setUrl(url);
return customer;
}
private Contact createContact() {
Contact contact = new Contact();
contact.setFirstName("John");
contact.setLastName("Doe");
contact.setPhone("1-800-111-1111");
contact.setShipAddress("475 LENFANT PLZ 10022 WASHINGTON DC 20260-00");
return contact;
}
Let's take a closer look at how to correctly work with transactions. Note that there are commit and rollback methods on both Transaction and TransactionManager. The difference is that the first one does not release the transaction (does not return it to the pool) and the second one does. In such a way we can decouple database transactions (which are marked by Transaction.commit()) and business ones.
Note that TransactionManager has methods begin() and commit(...) that throw SQLException, and also its doubles beginUnchecked() and commitUnchecked(...) that throw RuntimeException which can be used alternatively providing for shorter syntax. Also there is a double for TransactionManager.rollback(...) method – TransactionManager.rollbackSilently(...). It does not throw any exception – only logs it. It is well suited for use in finally clauses since it will not shadow any previous exceptions.
ODAL comes with its own java.sql.DataSource implementation. It can be used independently and even compiled into a separate jar file if desired. It is simple yet powerful. It features configurable timeout on DataSource.getConnection() method (connectionWaitTimeout) which prevents deadlocks even with buggy programs. It also has optional check for bad connection (ping) capability, to remove bad database sessions from the pool, and prepared statements caching.
Instantiation of the data source is very simple:
DefaultDataSourceFactory dataSourceFactory = new DefaultDataSourceFactory(properties);
DataSource dataSource = dataSourceFactory.newDataSource();
Below is a sample properties file:
driver=org.hsqldb.jdbcDriver
url=jdbc:hsqldb:file:hsqltestdb
user=sa
password=
maxConnections=20
stmtCacheSize=100
connectionWaitTimeout=20000
checkForBadConnection=true
For other configurable parameters see the API.
All ODAL classes are either controllers (“doers”) or models (“descriptors”). Controllers know “how”, models know “what”. Models are all about data structures, agnostic of the way this data is stored or retrieved. On another hand, models are not just “any” Beans. The model classes are all descendants of the PersistentObject.
As we already mentioned, in ODAL fall into two major categories. The first one is basic persistent objects. These are the ones mapped one to one to database tables. The second category is composite or composites. They are compositions of the basic persistent object.
The main feature of the PersistentObject class is that it is not “flat”. If we take a look at its simplified class diagram below
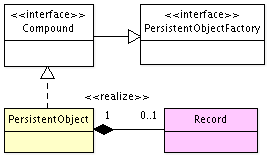
we can notice that PersistentObject class contains Record instance. Record is the class where the most of the things “happen” for PersistentObject. Record contains PersistentObject's current and original state, database meta data, and so on. To a degree PersistentObject is a wrapper for the Record class. PersistentObject by itself does not have any data fields and the only access to data is through the Record class. Generated classes, on another hand, descendants of PersistentObject, have data Bean fields that are duplicates of the Record data. This design lets PersistentObject be flattened and unflattened. Flattened PersistentObject does not contain Record instance and can be used for either caching when application memory footprint is of importance or simply as a read-only data snapshot.
Record class contains meta data which can be accessed through its Record.getTable() method. Record class also contains original and current values of its fields. Record fields fields can be accessed either by name which coincides with that of column name in the basic persistent object descriptors or by index. Let's look at the following code fragment taken from one the generated persistent classes,
private Long customerId;
.....
//
// customerId:
//
public Long getCustomerId() {
return this.customerId;
}
public void setCustomerId(Long customerId) {
if (record2().setObject(ICOL_CUSTOMER_ID, customerId)) {
this.customerId = customerId;
}
}
public boolean izNullCustomerId() {
return record2().getObject(ICOL_CUSTOMER_ID) == null;
}
public void setNullCustomerId() {
if (record2().setObject(ICOL_CUSTOMER_ID, null)) {
this.customerId = null;
}
}
............
public Record record2() {
invalidateOnFlattened();
return record;
}
These are 4 methods that get generated for each persistent object field that is mapped to a database column. You can see that in setters the value gets set to Record and also to a field. Attempt to call any of field accessors or modifiers other than a getter on flattened object will cause OdalRuntimePersistencyException.
The field values can be set directly to the Record. In this case to synchronize Record with its parent PesistentObject, PesistentObject.toBeanFields() should be called. Whenever a setter method is called on PesistentObject field and the original field value is different from the new one the field becomes “dirty”. You can check if particular field is dirty by calling isFieldDirty(...) method of the Record class. You can check if record as a whole is dirty by calling its isDirty() method. If record has never been saved to or retrieved from database then any setter call makes field dirty. Only dirty fields get saved in database. Occasionally, you will find it convenient not to overwrite record's value with nulls. In this case you can set setNotOverwriteWithNulls(...). You also may not want to save records that have only primary key values populated. Use setSkipInsertForKeysOnly(...) method in this case.
PersistentObject class provides several copy methods that allow for copying one PersistentObject into another (see the API documentation).
Generated persistent object classes always have 2 constructors – the default one with no arguments and the one with primary key fields. When inheriting from the generated object remember to always implement the no arguments constructor.
What is the difference between basic persistent object and a composite one? Simple answer is that composite persistent object is the one that returns true from one of these methods: PersistentObject.complex() or PersistentObject.compound(). That means that composite is basic persistent object with enabled complex or compound features.
To better understand what compound object is we have to ask ourselves why would we need one?
Imagine a set of tables with one-to-one relationships that really represent one logical object and on Java level you would want them to behave like one. This is the situation were use of compound object is appropriate.
If we go deeper we can reminisce the theory of O-R mapping with regards to object inheritance. Martin Fowler mentions three patterns: Single Table Inheritance, Concrete Table Inheritance and Class Table Inheritance.
Single Table Inheritance uses one table to store all the classes in hierarchy. Concrete Table Inheritance uses one table to store concrete class in hierarchy. Class Table Inheritance uses one table for each class in hierarchy.
Let us consider how to model them in ODAL. Single Table Inheritance is trivial, you generate a basic persistent class and you inherit from it as many times as you want.
Concrete Table Inheritance cannot be reproduced in ODAL since ODAL generates separate class per table. However, it can be simulated by use of interfaces instead of classes.
Class Table Inheritance, the most meaningful pattern out of three, can be fully expressed in ODAL and it is well-suited for use of compound objects. Simplified table and class hierarchies describing Class Table Inheritance are shown below.
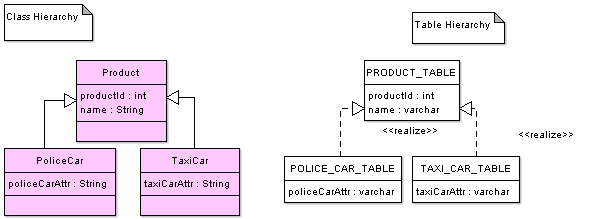
Let us take a look at how this pattern is implemented in ODAL.
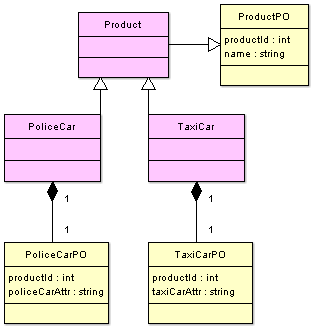
Compound composite objects are shown in pink, basic that map one-to-one to the database tables are in yellow. As you can see, PoliceCar and TaxiCar classes inherit to Product and contain instances of basic PoliceCarPO and TaxiCarPO, respectively. PoliceCar gets all the attributes that the Product has and additional attributes from the PoliceCarPO class.
There are two ways to add child fields to a compound composite: one is with containment type “has”, another – with containment type “is”. In the first case, the generated object would have one accessor and one modifier per child (to get or set PoliceCarPO, in our case). When the “is” containment type is used, the generated object would have all the child class accessors and modifiers added to a resulting composite.
Child entries of a compound object can only be (at least for now) basic persistent objects.
To generate the class hierarchy we have to create a proper entry in the composite descriptor file. Below is a sample of a composite descriptor with the fragment that produces desired object hierarchy,
#
# Descriptor to generate test complex & compound objects
#
{
.................
objectsReferences = {
#-----------------------------------------------------------------------#
# Compound delegating factory objects:
#-----------------------------------------------------------------------#
CPD_PRODUCT = {
className = "Product"
#interfaceName = "ICpdTestProduct"
base = {
name = PRODUCT # Required: Name of one of objectsReferences from this file
# or alias from external descriptor
# className = "ProductPO" # Optional
}
compound = {
delegateFactory = {
className = com.completex.objective.components.persistency.core.impl.CompoundDelegateFactoryImpl
delegatePersistentObjects = [ "com.Product"
"com.TaxiCar"
"com.PoliceCar" ]
delegateValues = [ "product" "taxiCar" "policeCar" ]
discriminatorColumnName = "ProductPO.COL_NAME"
}
}
}
#-----------------------------------------------------------------------#
# Compound object:
#-----------------------------------------------------------------------#
CPD_TAXI_CAR = {
className = "TaxiCar"
#interfaceName = "ICpdTestCar"
base = {
name = CPD_PRODUCT # Required: Name of one of objectsReferences from this file
# or alias from external descriptor
# className = com.Product # Optional class name
}
compound = {
children = {
taxiCarAttr = {
ref = {
name = TAXI_CAR_PO # Required: Name of
# the alias from external descriptor
className = com.TaxiCarPO # Optional class name
}
cascadeInsert = TRUE
cascadeDelete = TRUE
containmentType = is
}
}
}
}
#-----------------------------------------------------------------------#
# Compound object:
#-----------------------------------------------------------------------#
CPD_POLICE_CAR = {
className = "PoliceCar" # Generated class name
#interfaceName = "ICpdTestCar"
base = {
name = CPD_PRODUCT # Required: Name of one of objectsReferences from this file
# or alias from external descriptor
# className = XXX # Optional
}
compound = {
children = {
policeCarAttr = {
ref = {
name = POLICE_CAR_PO # Required: Name of
# the alias from external descriptor
className = com.PoliceCarPO
}
cascadeInsert = TRUE
cascadeDelete = TRUE
containmentType = is
}
}
}
}
#-----------------------------------------------------------------------#
} # End of objectsReferences
}
Each object reference in the descriptor file corresponds to a class to generate. Let's take a look at CPD_PRODUCT entry.
CPD_PRODUCT
className – Product, short name of generated class (its package is specified in the generator configuration file, composite-po-config.sdl ).
base – describes the parent of the generated class.
name – name of one of objects references from this file or table entry alias from external descriptor. PRODUCT, in this case, is the alias from the external descriptor.
compound – describes compound features of the composite.
delegateFactory. Presence of that entry means that this class is configured to instantiate other classes.
className – full name of the delegate factory class.
delegatePersistentObjects – array of class names to be instantiated when the values in the column specified in discriminatorColumnName entry is set to corresponding values in a delegateValues array.
delegateValues – see delegatePersistentObjects.
discriminatorColumnName – the table column name which values are used as keys indicating to Persistency what classes are to instantiate. It is a string that gets interpreted either literally or as a the generated constant if it has a '.' character inside. In our case, When the values in ProductPO.COL_NAME (the generated constant) column are "product", "taxiCar", "policeCar", the Persistency will instantiate "com.Product", "com.TaxiCar", "com.PoliceCar" classes, respectively.
Let's take a look CPD_TAXI_CAR object reference.
CPD_TAXI_CAR
className
base
name – CPD_PRODUCT is reference to CPD_PRODUCT entry described earlier.
compound
children – sub-references to basic which fields are to be added to the composite.
taxiCarAttr – sub-reference key. Its value is used to derive field, accessor and modifier names in case of “has” containment type.
ref – describes this sub-reference.
name – name of table entry alias from the external descriptor.
className – optional class name. If not provided – derived from the table entry alias (see previous paragraph).
cascadeInsert – TRUE, indicates that when the parent object is inserted the child will be inserted too.
cascadeDelete – TRUE, indicates that when the parent object is deleted the child will be deleted too.
containmentType = “is” indicates, as we stated before, that all the child class accessors and modifiers added to a resulting composite.
Complex object is a composite with parts being relatively independent allowing for lazy loading, for example. In contrast to a compound, complex object can represent one-to-many and many-to-one as well as one-to-one relationships.
Let us say we have an Order and OrderItem objects as it is shown at the diagram below.
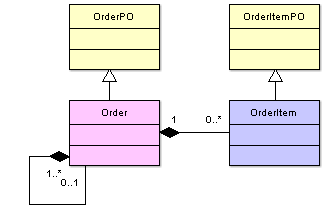
Here OrderPO and OrderItemPO are basic persistent objects. Order is a complex one. It can have several order items and also it has a reference to the parent order which is depicted as a reference to itself.
The corresponding entry in the composite descriptor file is as follows,
CPX_ORDER = {
className = "Order" # Optional - otherwise derived from the key name
# interfaceName = # Optional - otherwise derived from the key name
base = {
name = CUSTOMER_ORDER
className = OrderPO
}
complex = {
children = {
orderItem = {
relationshipType = one_to_many
ref = {
name = ORDER_ITEM
className = com.OrderItem
}
lazy = TRUE
cascadeInsert = TRUE
cascadeUpdate = TRUE
cascadeDelete = TRUE
multipleResultFactory = {
className = com.completex.objective.components.persistency.type.TracingArrayListCollectionFactory
# constructorArgs = [ true true ]
}
}
parentOrder = {
relationshipType = many_to_one
ref = {
name = CUSTOMER_ORDER
className = Order }
lazy = TRUE
cascadeInsert = TRUE
cascadeUpdate = TRUE
cascadeDelete = TRUE
}
}
}
}
Below is an explanation what the sub-entries of the CPX_ORDER mean.
CPX_ORDER
className – Order, short name of generated class (its package is specified in the generator configuration file, composite-po-config.sdl ).
base – describes the parent of the generated class.
name – name of one of objects references from this file or table entry alias from external descriptor. CUSTOMER_ORDER, in this case, is the alias from the external descriptor.
className – OrderPO, optional name of the parent class. If not specified it would have been resolved through the name reference (see previous paragraph).
complex – describes “complex” features of the composite.
children – sub-references to child persistent objects.
orderItem – the 1st sub-reference key. Its value is used to derive field, accessor and modifier names.
relationshipType – one_to_many, relationship to the parent, Order in this case, object. It should correspond to the ones on the database tables level.
ref – describes this sub-reference.
name - ORDER_ITEM, name of table entry alias from the external descriptor.
className – com.OrderItem, name of the basic persistent object or its descendant class.
lazy – TRUE, indicates that order items collection is to be loaded in “lazy” fashion.
cascadeInsert – TRUE, indicates that when the parent object is inserted the child will be inserted too.
cascadeUpdate = TRUE, indicates that when the parent object is updated the child will be updated too.
cascadeDelete = TRUE, indicates that when the parent object is deleted the child will be deleted too.
multipleResultFactory – describes the collection factory to be used when retrieving the order items collection.
className – class name of the collection factory .
parentOrder - the 2nd sub-reference key.
relationshipType – many_to_one, relationship to the order, meaning that one parent order can have several orders.
ref
name – CUSTOMER_ORDER.
className – com.Order.
lazy – TRUE.
cascadeInsert – TRUE.
cascadeUpdate – TRUE.
cascadeDelete – TRUE.
You could notice that many-to-many relationship type was not mentioned when describing composites. It is officially not supported by ODAL. This is done purposely, since many-to-many mappings potentially bring more problems than they resolve. Though, it can be represented in terms of several one-to-many, many-to-one relationships, it is not recommended to do that.
Compound objects cannot have circular dependencies since their child entries always refer to basic persistent objects. Complex objects, on another hand, can have circular dependencies on class level.
When the object first instantiated ODAL pre-compiles its link dependency graph and identifies all the dependencies including the circular ones on the class level. Link dependency graph is used whenever the object is retrieved in non-lazy manner, so the framework knows where to stop the retrieval without going into infinite loop.
Consider an example where we have class A that contains child named “slave” referencing class B – {slave=B} which, in its turn, has a child {master=A}. When dependency graph gets pre-compiled, ODAL collects {A, B, slave} link, {B, A, master} link, then it encounters {A, B, slave} link again and marks it “the end of the chain”. On load of A, sequence A -> B will only be retrieved once.
When the class references itself, like when A has a child {link=A}, the sequence A->A will also be retrieved once.
It should be mentioned that even though ODAL supports circular dependencies, we would strongly advice against using them, except may be for cases of self-dependencies. Circular dependencies, in general, complicate object structure limiting their re-usability and reducing maintainability. With no circular dependencies you can freely use inheritance. In case of circularly dependent objects, you have to make sure that the classes in mutual references are the same (not just some their descendants) since otherwise the executed query chain may be longer that you expected.
ODAL does not keep an internal object cache and hence, if you retrieve object A{id=1} several times, the queries will also be executed several times each time returning a new A instance. As a consequence, bi-directional dependencies on object level are not supported.
Composites can combine compound and complex features. We can imagine, for instance, PoliceCar class, defined before as a compound object, having a tree of extra attributes which could be described in terms of complex features. Every such a combination should be thoroughly thought through since the more complicated the object becomes the less chances you have to reuse it and the less control you have over it.
There two other types of worth mentioning here. One of them is CompoundPersistentObject. CompoundPersistentObject is convenient when you have to retrieve rows of data consisting of records coming from different tables. Internally, it contains an array of persistent objects. You can combine the generated, strictly typed, with generic ones of AdHocPersistentObject type.
Let's say the result of the query exactly matches records of Customer and Order but contains one extra field, rownum, for example. The CompoundPersistentObject that can serve as a container for this data can be instantiated as follows,
AdHocPersistentObject adHocPersistentObject = new AdHocPersistentObject(1);
adHocPersistentObject.setColumnName(0, "rownum");
CompoundPersistentObject singularResultFactory = new CompoundPersistentObject(new PersistentObject[]{new Customer(), new Order(), adHocPersistentObject});
We used here AdHocPersistentObject to retrieve “rownum” column that does not exist in any of the generated objects. It will be discussed later in more details.
implement java.io.Externalizable interface methods. You can choose to use them in which case
implements="java.io.Externalizable"
must be set in the generator configuration file. It is set by default in the configuration template file. When the default serialization mechanism is used, serialized, modified and serialized back “remember” their original as well as modified states which allows for selective field update without synchronization with a database. Flattened cannot be serialized through Externalizable interface methods.
You can serialize flattened using simple Java serialization. In that case you have to set
implements="java.io.Serializable"
in the generator configuration file.
Alternatively, you may choose to implement your own serialization mechanism.
ODAL provides PoOutputStream and PoInputStream (see com.completex.objective.components.persistency.io.obj.impl package) implementations of ObjectOutput and ObjectInput interfaces respectively that allow to specify the serialization mode – preserving original values or not – while using non-flattened persistent objects.
also can be serialized in XML format using XmlPersistentObjectOutputStream and XmlPersistentObjectInputStream implementations of ObjectOutput and ObjectInput interfaces (see the API for more information).
Transaction has to be created before any database operation. Transactions are created through TransactionManager interface. ODAL transaction combines features of both database session and database transaction. That means that when you call Transaction.commit() or Transaction.rollback() methods transaction does not die. You can repeatedly call Transaction.commit() the same way you do it in database session. To finalize transaction you have to call commit or rollback on TransactionManager at which point the transaction gets released and returned back to the pool.
TransactionManager supports flat as well as pseudo-nested transactions. Below is an example that features use of pseudo-nested transactions,
public void createCustomerWithProfile() throws CustomerException {
Transaction transactionOuter = null;
Transaction transactionInner = null;
try {
transactionOuter = getTransactionManager().begin();
createCustomer();
String errorReason = null;
try {
transactionInner = getTransactionManager().begin();
createCustomerOptionalProfile();
persistency.getTransactionManager().commit( transactionInner );
} catch (Exception e) {
//
// This is not a fatal:
//
errorReason = e.getMessage();
if ( transactionInner != null ){
getTransactionManager().rollback( transactionInner );
}
}
updateCustomer(errorReason);
// Commit w/o returning transaction to the pool
transactionOuter.commit();
} finally {
if ( transactionOuter != null ){
// Now return the transaction to the pool
getTransactionManager().rollback( transactionOuter );
}
}
}
In the example, the Customer and its profile are created in two pseudo-nested transactions. The inner transaction is not considered a critical one, therefore if an exception happens it simply rolls back while the outer one commits. The TransactionManager keeps track of the order in which the transactions were created and it will throw RuntimeException if the order of commit(transaction)/rollback(transaction) calls is wrong. The rule is that you have to call commit(transaction)/rollback(transaction) for the inner transaction before the outer one.
ODAL provides TransactionListener interface that being registered with transaction will receive events notifications through its methods afterCommit() and afterRollback(). You can perform cleanup of resources related to that transaction, put extra logging and so on. You can add or remove listeners with Transaction.addListerner(String key, TransactionListener listener) and Transaction.removeListerner(String key) methods, respectively.
Imagine that you wrote a component that has to persist objects to a database and you wrote it in such a manner that it starts and commits transactions by itself. Imagine again that tomorrow you realize that you have to reuse this component in context of another application, container, etc., and you want to disable this component ability to control transactions. Sure, you can always find some framework that will allow you to extract the transaction functionality into an aspect, for example, by modifying byte code or a container that will offer you ability to declaratively modify transaction boundaries. But what if you want this component to actually be independent on container, or you do not appreciate byte code modification, or just do not want to change your code?
With ODAL you can achieve the desired behaviour as follows. Your component has to be persistence aware. However, instead of passing just an instance of Persistency to it, you will pass LightPersistency and TransactionManager instances separately, ensuring that the component cannot get a TransactionManager from persistence directly. Now, if you want this component to be able to control its transactions – you pass to it the TransactionManager instance that you get from Persistency (or the same TransactionManager instance the Persistency was initialized with). If you want restrict this ability, ODAL offer the mechanism of Joining Transaction Managers. To restrict the component ability to start and finish business transactions without restricting it ability to commit or rollback you have to initialize it with TransactionManager instance created as follows,
DefaultTransactionManagerFactory factory = ...;
TransactionManager tm = factory.newTransactionManager();
TransactionManager joiningTm = factory.newJoiningTransactionManager(tm);
component.setTransactionManager( joiningTm );
You can also completely deprive the component ability to control transactions as it is shown below,
DefaultTransactionManagerFactory factory = ...;
TransactionManager tm = factory.newTransactionManager();
TransactionManager joiningTm = factory.newJoiningNullTransactionManager(tm);
component.setTransactionManager( joiningTm );
To turn on JTA support you have to initialize DefaultTransactionManagerFactory as follows,
DatabasePolicy policy = DatabasePolicy.DEFAULT_ORACLE_POLICY;
DefaultTransactionManagerFactory tmFactory = new DefaultTransactionManagerFactory();
tmFactory.setDataSource(dataSource);
tmFactory.setDatabasePolicy(policy);
TransactionManager transactionManager = tmFactory.newTransactionManager();
transactionManager.setType(DefaultTransactionManagerFactory.TYPE_JTA);
transactionManager.setUserTransactionName (jndiUserTransactionName);
Sometimes when you work with legacy applications you can encounter a situation where you have absolutely no control over the way database connections are being created. Basically, you are given a connection and have to use it. ODAL provides a specialized transaction manager for such case – PrimitiveTransactionManager. To instantiate it use DefaultTransactionManagerFactory.TYPE_JDBC_PRIMITIVE as manager type. With this transaction manager you have to use different method to begin transaction, namely begin(Connection connection) or beginUnchecked(Connection connection). Both of them will just create a wrapper around the connection object without actually opening a new connection.
do not save or retrieve themselves. They are used more like data containers. To save or retrieve data to or from a database ODAL offers several interfaces or APIs. You can chose the most appropriate one depending on required level of control. The most frequently used will be Persistency or LightPersistency.
Retrieving in ODAL is done in two ways. The first and the most generic one is through the Query API. In this case the query is created and passes as an argument to one of the Persistency methods. The second way is when a persistent object class is passed as an argument in which case an object or a collection of objects of the same type is returned as a result. The second way is also known as “Query-By-Example” (QBE).
As we mentioned before, the generated persistent classes always have a constructor with primary key fields as arguments. If you already know those values you can load the persistent object using that constructor through the load method.
Customer customer = persistency.load(new Customer(customerId));
The Customer object reference passed as an argument is different from the one returned as a result. This is true for all QBE methods. If nothing is found then null value is returned. Persistency.load(...) method ignores any other fields of the QBE parameter object except for the primary key ones if they are populated. If the primary key fields are nulls in the QBE parameter object then OdalPersistencyException is thrown.
You can perform simple queries by using QBE method. Let's say we do not know what the customer id is but we know the first and the last name of the customer. In this case we can retrieve collection of Customer objects satisfying this criteria as follows,
Customer customerQuery = new Customer();
customer.setFirstName(“John”);
customer.setLastName(“Smith”);
Collection customers = persistency.select( customerQuery );
If none is found an empty collection is returned.
In QBE methods, the fields that are set on the object passed as a parameter (“example” object) are joined by "AND" into SQL where clause.
If we know that the first/last name pair uniquely identifies the Customer in our system then we could use persistency.selectFirst() method.
Customer customerQuery = new Customer();
customer.setFirstName(“John”);
customer.setLastName(“Smith”);
Customer customer = persistency.selectFirst( customerQuery );
Persistency.selectFirst(...) returns null if no customer matching our criteria is found.
In QBE with compound object, parameters from all the compound entries are taken into account when building the SQL condition. In this respect it behaves like one entity.
In QBE with complex object, only parameters set on the master (root) object are are taken into account when building the SQL condition. For example, in the previously mentioned Order/OrderItem complex object, only fields set on the Order would get into SQL condition.
Sometimes QBE is not enough because of its limited capabilities. In such cases ODAL offers more powerful way to query a database – with Query API. Query API provides set of methods that enable creating SQL statements making them database independent (relatively, of course) and at the same time staying close enough to the database for flexibility reasons.
Let us say, we want to retrieve all the customers that where created between certain dates and who were born in 1979. Below is the example that does it,
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MMM-dd");
Query query = persistency.getQueryFactory().newQuery(new Customer());
query.addToWhere(Customer.COL_CREATION_DATE).addToWhere(query.between("?", "?"))
.andToWhere(Customer.COL_BORN_YEAR).addToWhere(" =? ");
query.addParameter(dateFormat.parse("2006-May-01"));
query.addParameter(dateFormat.parse("2006-Dec-01"));
query.addParameter("1979");
Collection customers = persistency.select(query);
Query.newQuery(...) method takes object factory as a parameter (see PersistentObjectFactory). Object factory does have to be created every time and can be a static field or cached. You can also specify what type of collection you want to return by specifying multiple result factory,
query.setMultipleResultFactory(ArrayListCollectionFactory.factory());
Several CollectionFactory implementations, which can be used as multiple result factories, are provided. If none is set – the default one, ArrayListCollectionFactory, is used. ODAL implementations include lists and sets.
Query parameters are positional. When adding a parameter you can explicitly specify its type with Query.addParameter(ColumnType type, Object parameter) method. However, if missing it will be correctly extrapolated by the framework in most of cases, except, of course, for the ones with null values.
Note that we used the generated column name constants instead of just strings. As mentioned before this method provides for better code maintainability and therefore is recommended.
Queries are not thread safe. After the execution, query object becomes closed and cannot be reused.
Queries get compiled by the framework. Result of such compilation is an SQL statement which is available though the query.getSql() method. This mechanism can be used to create SQL fragments or sub-queries,
Query subQuery = persistency.getQueryFactory().newQuery();
.....
Query query = persistency.getQueryFactory().newQuery();
...
query.addToWhere( subQuery.compile().getSql() );
In real life application you frequently start with something simple and at some point find out that you have to enhance it to meet the requirements. Query API provides you with a way to do that. Let's say the first requirement was to get all the customers named “John”. So we created it using simple query-by-example,
Customer customerQuery = new Customer();
customer.setFirstName(“John”);
Collection customers = persistency.select( customerQuery );
After that, the requirement had changed to get all the customers named “John” but created between certain dates. We cannot achieve that by simple query-by-example method. However, can we re-use any of the old code? The answer is yes,
Customer customerQuery = new Customer();
customer.setFirstName(“John”);
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MMM-dd");
Query query = persistency.getQueryFactory().newQueryByExample(customerQuery);
query.andToWhere(Customer.COL_CREATION_DATE).addToWhere(query.between("?", "?"));
query.addParameter(dateFormat.parse("2006-May-01"))
.addParameter(dateFormat.parse("2006-Dec-01"));
Collection customers = persistency.select(query);
Instead of newQuery(...) method, we used newQueryByExample() which adds fields set on the Customer object to both SQL statement and the parameters. When building our where clause we start with query.andToWhere() which prepends the expression in the brackets with “ AND “. Actually, you can safely use andToWhere()at the beginning of the where clause since it is smart enough not to put “ AND “ immediately after “WHERE”.
Occasionally, you will find that you have to create a query that joins two or more tables. Query API provides flexible database independent way to create queries with joins. Historically, some bigger database vendors created their own way to express joins in SQL statements. Nowadays, most of them support SQL-92 standard. ODAL DatabasePolicy implementations for Oracle and Sybase provide methods to chose between native and ANSI query standards. In examples below we show the way to join the tables and the SQL fragments they result to,
Query query = persistency.getQueryFactory().newQuery(new Master());
Join join = query.addJoin(Master.TABLE_MASTER);
join.addInnerJoin(Slave.TABLE_SLAVE,
new String[]{Master.TCOL_MASTER_ID},
new String[]{Slave.TCOL_MASTER_ID});
SQL statement (ANSI):
"SELECT TEST_MASTER.TEST_MASTER_ID, TEST_MASTER.NAME, TEST_MASTER.DESCRIPTION, TEST_MASTER.CREATION_DATE, TEST_MASTER.LAST_UPDATED
FROM TEST_MASTER INNER JOIN TEST_SLAVE ON (TEST_MASTER.TEST_MASTER_ID = TEST_SLAVE.TEST_MASTER_ID)"
SQL statement (Oracle native):
"SELECT TEST_MASTER.TEST_MASTER_ID, TEST_MASTER.NAME, TEST_MASTER.DESCRIPTION, TEST_MASTER.CREATION_DATE, TEST_MASTER.LAST_UPDATED
FROM TEST_MASTER,
TEST_SLAVE
WHERE TEST_MASTER.TEST_MASTER_ID = TEST_SLAVE.TEST_MASTER_ID"
Similarly, left and right outer joins are done using join.addLeftJoin() or join.addRightJoin() instead.
When the query returns data from several tables you have two alternatives. One is to bring it back in the generic PersistentObject objects. The second is to use the generated descendants. In the first approach you do not set singular result factory on the query object or set it to null. The second approach, in its turn, has two strategies.
The first strategy, more appropriate for ad-hoc queries, is to use CompoundPersistentObject as a singular result factory. Let's say we need to bring all the orders that belong to a certain customer together with order items in specific state,
OrderItem queryOrderItem = new OrderItem();
queryOrderItem.setState(state);
Order queryOrder = new Order();
queryOrder.setCustomerId(customerId);
CompoundPersistentObject compoundQuery = new CompoundPersistentObject(new PersistentObject[]{queryOrder, queryOrderItem});
Query query = persistency.getQueryFactory().newQueryByCompoundExample(compoundQuery);
Collection compounds = persistency.select(query);
for (Iterator iterator = compounds.iterator(); iterator.hasNext();) {
CompoundPersistentObject persistent = (CompoundPersistentObject) iterator.next();
Order order = (Order) persistent.compoundEntry(0);
OrderItem orderItem = (OrderItem) persistent.compoundEntry(1);
}
In the example above, we use QBE approach in conjunction with CompoundPersistentObject. Internally, CompoundPersistentObject contains set of PersistentObject entries which are accessed by index. When returned compound entries are found in the same order as when they were placed in the CompoundPersistentObject passed as singular result factory to the query or to the query factory. Note that we did not add join to the query – it was created automatically based on the foreign key relationship between Order and OrderItem since we used QueryFactory.newQueryByCompoundExample method (see the API documentation). Of course, we could set the join ourselves and it would supersede the automatic one.
The second strategy is more appropriate for the stable aggregations of the when you want several basic to behave as one. For example, when our objects containment or inheritance is mapped to a corresponding table hierarchy. In this case, you create a persistent object as a composite one with compound features enabled. After that you use it in QBEs and in queries as if it was a basic persistent object.
Query interface provides an easy way to check the generated SQL statement,
String sql = query.compile().getSql();
This can also be utilized to create sub-query SQL fragments.
ODAL explicitly supports union queries. Below is an example of a query that combines data of Customer and HistoricalCustomer with specific first and last names.
//
// Create 1st query (master):
//
Customer customer = new Customer();
customer.setFirstName(“John”);
customer.setLastName(“Smith”);
Query query = persistency.getQueryFactory().newQueryByExample(customer);
//
// Create 2nd query (sub-query):
//
HistoricalCustomer historicalCustomer = new HistoricalCustomer();
historicalCustomer.setFirstName(“John”);
historicalCustomer.setLastName(“Smith”);
Query query2 = persistency.getQueryFactory().newQueryByExample(historicalCustomer);
//
// Add 2nd query to the union:
//
Union union = query.union(query2, UnionMode.UNION);
union.addToOrderBy("1", Query.ORDER_DESC);
union.addToOrderBy("2", Query.ORDER_ASC);
query.addParametersArray(query.collectInnerUnionParameters());
Collection collection = persistency.select(query);
for (Iterator iterator = collection.iterator(); iterator.hasNext();) {
Customer unionCustomer = iterator.next();
}
In ODAL, queries used for the union are not equal. The 1st query is the “master”. All its parameters are automatically added to the query object. The next queries that are added with union() method are called inner queries. Their parameters can be collected using query.collectInnerUnionParameters() method and added with query.addParametersArray(...) method or separately. Note that in the example above we added ORDER BY clause to the Union itself using ordinal column references since theoretically the columns of the sub-queries can have different names. Retrieved objects are of type Customer, that is the one defined by the master query.
ODAL offers lazy loading feature for child objects regardless whether it is a single object or a collection. You can specify the way child objects are loaded in the composite descriptor file. Below is an example of how to retrieve a branch of an object tree of an Order class that has a parent reference to itself,
Order order = (Order) persistency.load(new Order(orderId));
while(order.getParentOrder() != null) {
order = order.getParentOrder();
}
At the end of the cycle order will contain the reference to the root of the branch.
Attempt to lazy-load a child object outside of transaction will cause an exception.
Lazy loading should be used with caution. Unless the object tree is fully retrieved, any component that receives the object as a parameter and calls a getter that is defined to lazy-load a child object can potentially hit the database at that moment. Such behavior may be undesirable, let alone the fact that it, in a way, breaks the encapsulation principle. ODAL offers a method to alleviate this problem with flattening the objects. One of the flattening side effects is that it “freezes” the object retrieval.
Occasionally, you will find that you need to transform query result in some way. ODAL allows you to do it while retrieving. If you look at Persistency interface you can notice that every select method has its twin that takes one more parameter, LifeCycleController. It is kind of a listener to Persistency events. You can chose to implement it yourself but it is easier to inherit from the BasicLifeCycleController or to instantiate the last one as an anonymous class. Let us say we have a task to retrieve all the customer orders into a map that has “status” as a key and Order instance as a value. We could of course retrieve it first into a collection and with the second loop transform it into a map. However, we can do it more efficiently in one cycle. Snippet below shows how to do that.
final HashMap ordersByStatus = new HashMap();
Order orderQuery = new Order();
order.setCustomerId(CUSTOMER_ID);
Query query = persistency.getQueryFactory().newQueryByExample(orderQuery);
query.setMultipleResultFactory(AbstractListCollectionFactory.NULL_LIST_FACTORY);
persistency.select(query, new BasicLifeCycleController(){
public void afterCompositeSelect(AbstractPersistentObject persistentObject) {
Order order = (Order) persistentObject;
ordersByStatus.put(order.getStatus(), order);
}
});
Note that we set multiple result factory to the NULL_LIST_FACTORY implementation. This prevents the default collection populating with Order objects. Of course, if you want the default or custom collection to be populated also, you do not have to do that.
With ODAL Query API you can dynamically build a tree of linked queries. It is convenient when creating generic searches or ad-hoc query components. In the example below we created a query tree consisting of master query retrieving Order and child query retrieving list of OrderItems linked to that Order and satisfying some extra condition.
Query masterQuery = queryFactory.newQueryByExample(new Order(ORDER_ID));
OrderItem orderItem = new OrderItem();
Query slaveQuery = queryFactory.newQuery(orderItem);
ChainedLink link = new ChainedLink(slaveQuery,
new int[]{Order.ICOL_ORDER_ID},
new int[]{OrderItem.ICOL_ORDER_ID},
Order.CHILD_ORDER_ITEM);
slaveQuery.andToWhere(OrderItem.ICOL_STATUS).addToWhere(“=?”);
slaveQuery.addParameter(“pending”);
masterQuery.addChild(link);
Collection result = persistency.select(masterQuery);
for (Iterator it = result.iterator(); it.hasNext();) {
Order order = (Order) it.next();
}
Slave query is linked to the master one with the ChainedLink named by the same name as child entry of the order – Order.CHILD_ORDER_ITEM. It would allow to use the generated getters and setters to access the order items.
ChainedLink requires for slave query to have a single result factory set to not null value which would normally be a generated persistent object. If you do not have a generated object and you do not care whether your result objects have Bean like accessors and modifiers you could link the queries with Link instance in which case the result would be a collection of generic PersistentObject instances. Fields are accessed through the record by name or index. Also, for each child query the result PersistentObject will have a child with the same name and it can be accessed by PersistentObject.getChildObject(String name) method. Previous example shows some low level manipulations assuming that we did not define any relationships between Order and OrderItem objects.
Let us assume that we defined Order - OrderItem parent-child relationship.
Query tree can in fact “rewire” your default object mapping. Let's say class Order has a list of child OrderItem objects that are configured for lazy loading, that is normally they would be loaded in 2 SQL statements. Imagine now that a some point we would like to retrieve Orders that have OrderItems in certain state and populate only those into the OrderItems list, and do it in one query instead of two (similar to what we did in previous example). You can actually do it with Query Tree mechanism. Below is the example of exactly that,
/**
* Load orders with only order items in certain state and having only those order items in the
* order items collection
*/
public Order [] loadOrders(Long customerId, String state) throws OrderException {
try {
OrderItem qbeOrderItem = new OrderItem();
qbeOrderItem.setState(state);
Order qbeOrder = new Order();
qbeOrder.setCustomerId(customerId);
qbeOrder.addOrderItem(qbeOrderItem);
Query query = persistency.getQueryFactory().newQueryByExample(qbeOrder);
// Inline order items query to retrieve everything in one SQL statement:
query.getChild(Order.CHILD_ORDER_ITEM).setInlineMode(Link.INNER_JOIN_MODE);
Collection orders = persistency.select(query);
return (Order[]) orders.toArray(new Order[orders.size()]);
} catch (OdalPersistencyException e) {
throw new OrderException(e);
}
}
This example is taken from the com.completex.objective.persistency.examples.ex003a.app.OrderDAO. Note that use of setInlineMode(Link.INNER_JOIN_MODE) method that forces using one joined query rather than two separate queries.
Persistent Objects allow you to reshape the result to fit your needs. Each Record contains a link object which is an entry point to the child Persistent Object or their collections. You can also dynamically modify the structure of of a Records' “flat” portion adding Persistent Entries (see Record.addPersistentEntry(String newColumnName, PersistentEntry entry) method). Persistent entry parameter can actually come from another Persistent Object. It is safe since the original one gets deep cloned and thus stays unchanged.
For queries that return single values you do not have to use a generic select method. ODAL provides easier way – through Persistency.selectSingle(Query query) method.
If you created your Query object or you have a persistent object created for QBE but all you need is to get count of records you can use Persistency.selectCount(...) method. Similarly, if you want to know if the query returns any results you can use Persistency.selectExists(...) method. That allows you to create a specific query or QBE factory and reuse it when you need to count records or check a database for records existence.
When you deal with large result sets it is a common practice to split data into pages. ODAL supports two types of paginated queries: Disconnected Page Query and Connected Forward Page Query.
Disconnected Page Query allows for random access to a required data page and gets detached from a database as soon as the page is retrieved. Disconnected Page Query is suitable for the Web or any other applications designed for user interaction. With query factory API you can either create a new Disconnected Page Query or transform an existing non-paginated query into a paginated one. The last technique is demonstrated below.
Query paginatedQuery =
persistency.getQueryFactory().newDisconnectedPageQuery(nonPaginatedQuery, new Page(3, 20));
Collection collection = persistency.select(paginatedQuery);
The paginated query is created here out of the non-paginated one and set to retrieve the 3rd page of 20 records.
Connected Forward Page Query allows only for sequential data page access and stays attached to a database until the end of processing session. Connected Forward Page Query is more suitable for a database batch like operations. In the following example we transform an existing non-paginated query into a paginated Connected Forward Page Query.
Query paginatedQuery =
persistency.getQueryFactory().newConnectedForwardPageQuery(nonPaginatedQuery, 20);
Collection persons;
while ((persons = persistency.select(paginatedQuery).size() > 0 ) {
// Do your processing here
}
Note that the paginated query is called repeatedly. That would fail with any other query type except for the Connected Forward Page Query. The query gets closed when the result set gets exhausted. You can interrupt Connected Forward Page Query after any page. The query stays open which does not cause any problem unless you decide to continue the retrieval in different transaction. In that case an SQLException will be thrown.
ODAL provides convenient way to serialize query trees as SDL strings with QuerySdlConverterImpl class. Saved queries can be later materialized and executed. It can be applied to save dynamically created searches or reports. Moreover, the materialized queries can be modified with regards to their structure, condition clause, and so on. If the query was executed before you may have to call Query.decompile() method to enable modification.
By default all objects within one Query (or rather one Query Tree) are put into QueryContext (see the API) which allows for correct object references resolution.
When resolving object references, ODAL relies on PersistentObject.toKey() rather than on equals() method. Two objects retrieved by the query will point to the same instance once their keys returned on toKey() method are equal. Default implementation of toKey() method is based on primary key fields.
Query context gets reset after each select or load method call. Thus, it will be reset after each page retrieval for paginated queries.
For lazily retrieved objects references will only be resolved if the getters are called within query context. To achieve this the getters have to be called from the LifeCycleController callback afterCompositeSelect() method.
Sometimes this feature is not desired. For batch like operations, for example, usually there is no need to resolve object references. Since collecting objects in query context consumes memory, it makes sense to disable this feature for such cases. Query context can be disabled at query level using Query.setDisableQueryContext() method, or globally at the Persistency instance level using DefaultPersistencyAdapter.setDisableQueryContext() or through DefaultPersistencyFactory.setDisableQueryContext() method.
Inserting is a very simple operation in ODAL. If you configured you composite objects to cascade insert then you have to populate non-generated values and call insert on Persistency, like in example below.
Order order = new Order();
// populate order fields
OrderItem orderItem1 = new OrderItem();
// populate order item fields
order.addOrderItem( orderItem1 );
persistency.insert(order);
orderId field in orderItem1 gets populated automatically by foreign key reference.
Attempt to repeatedly insert already inserted persistent object will cause an exception.
If persistence is not configured to run in batch mode (it will be discussed later), changes are sent to a database as soon as the insert method is called.
Occasionally, you may find necessary to insert already inserted (or just retrieved) persistent object into different database (represented by another Persistency instance). You do it using Persistency.pipeInsert(...) method. Following example shows how to do that,
Collection orders = persistency1.select(query);
for (Iterator it = result.iterator(); it.hasNext();) {
Order order = (Order) it.next();
persistency2.pipeInsert( order );
}
You can update basic persistent object as long as they have a primary key defined in their records metadata. Generated have metadata as static fields but generic PersistentObject allows you to dynamically modify or create the metadata from scratch in case you need to.
To update persistent object you have two options. One option is to retrieve the object from database, modify it and call Persistency.update(...) method. Another is to create a new instance of persistent object, populate its primary key as well as the fields you want to modify and call Persistency.update(...) method. Since in ODAL all update statements are dynamic, only “dirty” fields will be updated in the database.
ODAL optionally supports primary key update (see DefaultPersistencyFactory.setSupportKeyUpdate(...) method). If not configured to support primary key update but primary key update is detected, an exception will be thrown.
An example below shows how to save basic persistent object.
Customer customer = new Customer(CUSTOMER_ID);
customer.setUrl(“http://new.url.com”);
int rc = persistency.update( customer );
In non-batch mode the update method returns integer value indicating if the object was really updated in the database. If the object is not dirty then Persistency.RC_NON_DIRTY value is returned, if the database did not update the object – 0 is returned.
Updating composite with compound only features is very similar to updating of the basic persistent objects. You modify the object and pass it to Persistency.update(...) method. Internally, every compound entry gets updated individually.
What happens during update of composite with complex features depends on two things. First is whether the object was generated with “cascade update” option. If it was then all the individual basic persistent object that constitute it get updated. The second thing is what type of multiple result factory was used when defining the child entries. ODAL provides TracingCollection interface which is designed for the purpose of tracing changes. Tracing collections will optionally register all the inserts, deletes and updates happened to their entries. So on update child entries may also be inserted or deleted. Insertion or deletion to the tracing collections are based on object references but if you insert 2 objects with the same primary key you will get an exception when trying to save it do database.
TracingHashSet, TracingLinkedList and TracingArrayList implementations of TracingCollection interface can be found in com.completex.objective.components.persistency.type package.
In the example below, we assume that Order is a complex persistent object having children orderItems which are defined as its multiple result factory. The order without order items is first inserted. Then, one order item is added to the order and on its update the order item is inserted into the database.
order = new Order();
order.setParentOrderId(null);
order.setCustomerId(CUSTOMER_ID);
orderDAO.insertOrder(order);
OrderItem orderItem = new OrderItem();
orderItem.setProductId(productId);
orderItem.setQuantity(QUANTITY_ONE);
orderItem.setState(OrderItem.STATE_PENDING);
order.addOrderItem(orderItem);
orderDAO.updateOrder(order);
Sometimes you would need to add an extra SQL statement to a condition that is otherwise generated out of the persistent object. In which case you can use Persistency
update(PersistentObject persistentObject,
String extraWhere,
Parameters extraParameters)
method. It takes additional SQL string fragment that gets appended to a WHERE clause and extra parameters that can be required for it.
Deleting of is done by primary key.
If composite persistent object is configured to cascade delete then all their children will be deleted as well. In the example below the Order object is loaded together with its order items and then the whole three gets deleted
Order order = persistency.load(new Order(ORDER_ID));
persistency.delete(order);
Attempt to repeatedly delete already deleted persistent object will cause an exception.
If persistence is not configured to run in batch mode (it will be discussed later), changes are sent to a database as soon as the delete method is called.
There is an alternative delete method that is called Delete-By-Example. In Delete-By-Example method, the fields that are set on the object passed as a parameter (“example” object) are joined by "AND" into SQL where clause. With complex object, only values set on the master (root) object are are taken into account when building the SQL condition. In example below all the order items with status “new_expired”.
OrderItem orderItemExample = new OrderItem();
orderItemExample.setStatus(“new_expired”);
presistency.delete( orderItemExample );
Use this method with caution because if no values are set it will try to delete all the table records.
In addition to a Query interface (which in spite of its generic name deals with SELECT statements only), there is also ModifyQuery interface and their descendants UpdateQuery and DeleteQuery which, in turn, deal with deletes and updates. For example, the following query
UpdateQuery updateQuery = persistency.getUpdateQueryFactory().newQueryByExample(updateSetMaster, updateWhereMaster);
updateQuery.setLimit(10);
persistency.update(updateQuery);
will update 1st 10 records taking values set in the updateSetMaster Persistent Object to construct an SQL SET clause, and values from updateWhereMaster Persistent Object to construct the WHERE clause.
Similarly, DeleteQuery can be constructed. The following query
DeleteQuery updateQuery = persistency.getDeleteQueryFactory().newQueryByExample(updateWhereMaster);
updateQuery.setLimit(10);
persistency.deleteByExample(updateQuery);
will delete the 1st 10 records satisfying the condition set by the example updateWhereMaster Persistent Object.
Query API provides methods to specify a pessimistic lock type. There two methods that should be considered in that regard: Query.setLocked(LockType lockType), Query.setLocked(LockType lockType, String[] forUpdateOf) and Query.setTimeout(long timeout) which let you specify what lock type should be used and how long to wait (in seconds) until giving up.
See also Persistency API for select and load methods that use LockType as a parameter.
Optimistic lock columns are specified in the external descriptor file. If there is a version field that has a sequence generator configured for it, it would be a good candidate for one.
See VersionSequenceKeyGeneratorImpl in API documentation for sequence generators provided by ODAL.
If performance is critical for your application and its transactions contain a few modify operations you can consider running Persistency in Batch Modify mode. For that, you can to use DefaultPersistencyFactory.setUseBatchModify(...) method before getting the Persistency instance. In this case all the modifications done to the persistent object do not get to the database with insert/update/delete call but rather delayed until you either execute Transaction.flush() or commit/rollback methods.
When Persistency API is not enough and you want to “get dirty” there is a raw query approach to select operations. The example below shows how to use it when access to raw result set and the statement is of essence.
Transaction transaction = null;
try {
transaction = transactions.begin();
PreparedStatement preparedStatement =
transaction.prepareStatement(query.compile().getSql());
preparedStatement.setLong(1, 1);
preparedStatement.setString(2, "VALUE");
preparedStatement.setDate(3, new java.sql.Date(new Date().getTime()));
// ...
ResultSet rs = preparedStatement.executeQuery();
while (rs.next()) {
// ....
}
rs.close();
transaction.releaseStatement(preparedStatement);
} finally {
if (transaction != null) {
transactions.commit(transaction);
}
}
Note that instead of preparedStatement.close() we used transaction.releaseStatement(preparedStatement). It is of importance since ODAL does not provide (for several reasons) delegating PreparedStatement implementation and this is the only correct way to release (or close, if it is not cached) the statement.
When modifying by either persistent object or by example is not enough, you can always escape to Persistency.executeUpdate(String sql, Parameters parameters) method. It will execute any modify SQL statement.
ODAL provides set of batch oriented features, and data pipe is one of them. Occasionally there is need to “pipe” large amounts of data from one persistent storage to another. Code below show example of data transfer from main table to an archiving one by pages of 50 records:
String destTableName = TestMaster.TABLE_TEST_MASTER + "_HIST";
PipeImpl pipe = new PipeImpl(persistency, new PipeDestinationEntry(persistency, destTableName), 50);
pipe.executePipe(new TestMaster());
There is no need to open and close transactions with pipes – it is done internally.
For more information see Pipe interface API.
ODAL provides its own column data types to facilitate the transformations between database and Java types. ODAL column data types are derived from ColumnType class. ColumnType class has several constant fields that are the predefined ODAL column types. However, you can also create you own custom column type.
Column types are specified in the external descriptor files through the dataType attribute. The examples below show show two ways to specify the dataType attribute. The 1st is using the predefined ODAL column types, the 2nd – with custom column type.
# Predefined ODAL column type:
dataType = BOOLEAN_PRIMITIVE
# Custom column type:
dataType = com.completex.objective.components.persistency.test.TestColumnType
Column types are used when generating the to correctly resolve Bean field types and also at runtime while reading, writing and binding field or parameter values.
Table below shows ODAL internal column types together with their generated field type and the default JDBC types
Column Type Name | Generated Field Type | Default JDBC type |
BOOLEAN | Boolean.class | Types.VARCHAR |
LONG | Long.class | Types.INTEGER |
DOUBLE | Double.class | Types.DECIMAL |
NUMBER | Number.class | Types.DECIMAL |
BIGDECIMAL | BigDecimal.class | Types.DECIMAL |
CHAR | String.class | Types.VARCHAR |
STRING | String.class | Types.VARCHAR |
DATE | java.util.Date.class | Types.DATE |
TIMESTAMP | Timestamp.class | Types.DATE |
BINARY | InputStream.class | Types.BINARY |
BYTE_ARRAY | byte[].class | Types.BINARY |
BLOB | Blob.class | Types.BLOB |
DETACHED_BLOB | Blob.class | Types.BLOB |
CLOB | Clob.class | Types.CLOB |
DETACHED_CLOB | Clob.class | Types.CLOB |
CLOB_STRING | String.class | Types.VARCHAR |
OBJECT | Object.class |
|
LONG_PRIMITIVE | long.class | Types.INTEGER |
DOUBLE_PRIMITIVE | double.class | Types.DECIMAL |
BOOLEAN_PRIMITIVE | boolean.class | Types.VARCHAR |
At runtime column type is used in conjunction with type handler (see TypeHandler interface in the API documentation) that is actually doing the job of reading, writing and binding. Relationship between column types and type handlers may be implicit and explicit. DefaultPersistencyFactory implements TypeHandlerRegistry interface and provide means to map specific column type to a type handler. By default several type handlers are preregistered with the DefaultPersistencyFactory class as it is shown in the table below.
Column Type Name | Type Handler Class |
BOOLEAN | BooleanTypeHandler |
LONG | LongTypeHandler |
DOUBLE | DoubleTypeHandler |
NUMBER | BigDecimalTypeHandler |
BIGDECIMAL | BigDecimalTypeHandler |
CHAR | DefaultTypeHandler |
STRING | DefaultTypeHandler |
DATE | DateTypeHandler |
TIMESTAMP | DateTypeHandler |
BINARY | BinaryTypeHandler |
BYTE_ARRAY | ByteArrayTypeHandler |
BLOB | BlobTypeHandler |
DETACHED_BLOB | DetachedBlobTypeHandler |
CLOB | ClobTypeHandler |
DETACHED_CLOB | DetachedClobTypeHandler |
CLOB_STRING | ClobStringHandler |
BOOLEAN_PRIMITIVE | BooleanTypeHandler |
LONG_PRIMITIVE | LongTypeHandler |
DOUBLE_PRIMITIVE | DoubleTypeHandler |
ODAL can also handle cases when column type is unknown. For example, when you use Query.addParameter(Object value) method without explicitly specifying the column type. ODAL can do it only for not null values and for that purpose there are type handlers associated with value class. This association is used for binding only and preregistered with the DefaultPersistencyFactory handlers are shown in the table below.
Class Name | Type Handler Class |
Boolean | BooleanTypeHandler |
boolean | BooleanTypeHandler |
java.util.Date | DateTypeHandler |
java.util.InputStream | BinaryTypeHandler |
If there is no type handler registered for given column type or class DateTypeHandler is used.
ODAL provides set of serializable alternatives for basic binary data types. They are BYTE_ARRAY, DETACHED_BLOB and DETACHED_CLOB.
You can register different type handler instead of the default ones. For example ODAL uses BooleanTypeHandler as a default one to handle booleans. It translates boolean true/false to string “Y”/”N” values. ODAL also provides an alternative Boolean10TypeHandler that translates boolean true/false to string “1”/”0” values. In code this alternative boolean type handler is registered with the factory that is instance of DefaultPersistencyFactory.
factory.registerTypeHandler(ColumnType.BOOLEAN, new Boolean10TypeHandler());
factory.registerBindTypeHandler(Boolean.class, new Boolean10TypeHandler());
factory.registerBindTypeHandler(boolean.class, new Boolean10TypeHandler());
Registering type handlers for specific column types corresponds to the implicit association mentioned before.
It is possible that you are not satisfied with the type handlers provided by ODAL. In this case you can write your own and register it with ODAL. To do so you have to implement TypeHandler interface. You can do it from scratch however we recommend you to extend DefaultTypeHandler in which case the amount of code you have write is minimal. In most of the cases all you have to do is to overwrite DefaultTypeHandler.transformRead(Object data) and DefaultTypeHandler.transformBind(Object data) methods.
To create a custom column type you have to inherit from ColumnType class of one of its descendants (see ODAL API documentation). You can then associate it with one of existing or newly create type handlers either implicitly or explicitly. The implicit way was described before. Code snippet below shows a column type and corresponding type handler that is created to store Java Map object in a database VARCHAR column in SDL format.
public class TestColumnType extends ColumnType.StringColumnType {
public static final String TEST_TYPE = "TEST_TYPE";
private static final TestMapStringTypeHandler typeHandler =
new TestMapStringTypeHandler();
public TestColumnType() {
super(TEST_TYPE, Map.class, typeHandler);
}
}
public class TestMapStringTypeHandler extends DefaultTypeHandler {
public static final SdlReader SDL_READER = new SdlReaderImpl();
public static final SdlWriter SDL_WRITER = new SdlPrinterImpl();
public Object transformRead(Object data) throws SQLException {
if (data != null) {
try {
StringReader stringReader = new StringReader(((String) data));
return (Map) SDL_READER.read(stringReader);
} catch (IOException e) {
throw new SQLException("Cannot SDL_WRITER.write data : " + data);
}
} else {
return null;
}
}
public Object transformBind(Object data) throws SQLException {
if (data != null) {
StringWriter stringWriter = new StringWriter();
try {
SDL_WRITER.write(stringWriter, data);
} catch (IOException e) {
throw new SQLException("Cannot SDL_WRITER.write data : " + data);
}
return stringWriter.toString();
} else {
return null;
}
}
}
As you can see this new column type is explicitly associated with the type handler. Similarly, we could store this data in a CLOB field, in which case we would inherit from ClobTypeHandler instead of the default one.
Explicit association takes priority over the implicit one.
Column type gets registered with ODAL its name rather than reference is used as a key. If you create a custom column type and plan to register it with ODAL keep in mind that if column type with the same name is already registered it will be overwritten. If you are not sure it is always a good idea to check it with DefaultPersistencyFactory.isRegisteredTypeHandler(ColumnType columnType) method.
Custom column types having explicit association with their type handler do not have to be registered with ODAL. They can simply be specified in the external descriptors in which case their names can coincide with ODAL internal ones not causing without overwriting them.
Depending on the JDBC meta data provided by the driver ODAL can more or less accurately determine the data type. For example, Oracle drivers returns java.sql.Types.BLOB for the BLOB type column and java.sql.Types.CLOB for the CLOB column type which immediately allows ODAL to generate them as Blob and Clob. With other databases it may not be that easy. In some cases the driver will simply return java.sql.Types.BINARY as a binary column type in which case ODAL generated field type will be InputStream. You can work with it but not as conveniently as Blob or Clob.
java.sql.Types.BINARY returned as a column type does not mean it cannot be translated to BLOB. You have to read the database and the corresponding JDBC driver documentation to see which type can be correctly interpreted as BLOB or CLOB, for that matter. For example, for Postgres it is oid type that can be interpreted as BLOB. If you know that, you can modify the external descriptor dataType to BLOB to make ODAL generate Blob as the field data type.
In some cases you have to instantiate Blob or Clob objects to populate them to corresponding fields. ODAL provides BlobImpl and ClobImpl implementations that can be used for that purpose.
In case of Clob column type you can transparently translate it into String describing its dataType as CLOB_STRING in the external descriptor.
ODAL provides several key (or field value) generators that automatically populate values on insert or update operations. ODAL also provides the way to create your own generator implementations. Internal ODAL key generators are described in the table below.
Short Class Name | Description |
SimpleSequenceKeyGeneratorImpl | Generates next value based on database sequence. Used on insert. |
BulkSequenceKeyGenerator100 | Generates next value from the pool. The pool of 100 numbers is reserved with a single call to database. The database sequence is retrieved with SimpleSequenceKeyGeneratorImpl. Used on insert. |
OdalSimpleSequenceKeyGenerator | Generates next value based on ODAL database sequence emulation database sequence or auto-increment value (see below for details). To install it run appropriate script from $ODAL_HOME/sql directory |
OdalBulkVersionSequenceKeyGenerator100 | Generates next value from the pool. The pool of 100 numbers is reserved with a single call to database. The database sequence is retrieved with OdalSimpleSequenceKeyGenerator |
SimpleVersionSequenceKeyGeneratorImpl | Generates next version value based on database sequence. The database sequence is retrieved with SimpleSequenceKeyGeneratorImpl |
BulkVersionSequenceKeyGenerator100 | Generates next version value from the pool. The pool of 100 numbers is reserved with a single call to database. It is based on SimpleVersionSequenceKeyGeneratorImpl |
CreatedDateGenerator | Populates date field on insert |
LastUpdatedDateGenerator | Populates date field on insert and update |
EpochLastUpdatedGenerator | Populates numeric field on insert and update with epoch value: System.currentTimeMillis() / 1000L |
ODAL sequence generators fall into two categories: simple and bulk ones. Simple sequence generators retrieves the next value from database every time key has to be generated. The bulk ones reserve set of numbers per one database retrieval making them more efficient.
For the databases that do not support sequences, ODAL provides sequence emulation. To enable it you have to run the script that creates ODAL sequence table. The predefined scripts can be found in $ODAL_HOME/sql directory. To create it from scratch follow the pattern,
create table odal_sequence
(
name varchar(255) primary key,
value bigint
)
The script has to create a table with the “name” column that contains sequence name, and
the “value” column that contains integer number.
The external descriptor entry for sequence generator looks as follows,
keyGenerator = {
class = com.completex.objective.components.persistency.key.impl.SimpleSequenceKeyGeneratorImpl
staticAttributes = {
name = CONTACT_SEQ
table = # Optional attribute specifying the table used for storing ODAL sequences.
# If not set the default - "odal_sequence" - is used
sameTransaction = # Optional attribute specifying if the sequence has to be generated in the same transaction
# Default is false
}
}
where table and sameTransaction attributes are applicable for ODAL emulated sequences only.
Internal key generators do not overwrite value if it is already set unless it is null or 0 for numeric key generator. Exception is the version key generator that can be configured to force setting the value (see the API documentation).
More should be said about OdalSimpleSequenceKeyGenerator. It is created to allow for reusability of the generated with different databases. In cases when database supports explicit record level locks ODAL table based sequence generating mechanism can be used. For databases not supporting explicit record level locks, such as HSQLDB, alternative way to generate sequences (using database native sequences or auto-increment columns) can be used. For OdalSimpleSequenceKeyGenerator policy (see com.completex.objective.components.persistency.key.OdalKeyPolicy) is set to determine which sequence generating mechanism to use. With default policy if explicit record level locks are supported then ODAL table key generating method is give the highest priority, otherwise – the lowest. For more details see the API documentation.
To create a custom key generator you have to implement AutoKeyGenerator interface (see the API documentation).
With ODAL you can optionally generate life cycle controllers for the basic persistent objects. This option is controlled by generate_life_cycle_ctl attribute of the ODAL_HOME/config/ref/persistent-object-config.sdl file. These are classes look like
public class OrderItemPoCtl extends AbstractLifeCycleController implements PersistentRule {
public static final PersistentObject PERSISTENT = new OrderItemPO();
protected RecordValidator recordInsertValidator = new RecordValidatorImpl(PERSISTENT, true);
protected void initInsertValidator() {
/* COLUMN NAME: ORDER_ITEM_ID ; ALIAS NAME: ORDER_ITEM_ID */
initInsertValidatorOrderItemId();
/* COLUMN NAME: ORDER_ID ; ALIAS NAME: ORDER_ID */
initInsertValidatorOrderId();
/* COLUMN NAME: PRODUCT_ID ; ALIAS NAME: PRODUCT_ID */
initInsertValidatorProductId();
/* COLUMN NAME: QUANTITY ; ALIAS NAME: QUANTITY */
initInsertValidatorQuantity();
/* COLUMN NAME: STATE ; ALIAS NAME: STATE */
initInsertValidatorState();
/* COLUMN NAME: LAST_UPDATED ; ALIAS NAME: LAST_UPDATED */
initInsertValidatorLastUpdated();
/* COLUMN NAME: CREATION_DATE ; ALIAS NAME: CREATION_DATE */
initInsertValidatorCreationDate();
}
/* COLUMN NAME: ORDER_ITEM_ID ; ALIAS NAME: ORDER_ITEM_ID */
protected void initInsertValidatorOrderItemId() {
//getRecordInsertValidator().addFieldValidator(OrderItemPO.ICOL_ORDER_ITEM_ID, new NumberSizeFieldValidator(new BigDecimal("-"), new BigDecimal("")));
}
/* COLUMN NAME: ORDER_ID ; ALIAS NAME: ORDER_ID */
protected void initInsertValidatorOrderId() {
getRecordInsertValidator().addFieldValidator(OrderItemPO.ICOL_ORDER_ID, new RequiredFieldValidator());
//getRecordInsertValidator().addFieldValidator(OrderItemPO.ICOL_ORDER_ID, new NumberSizeFieldValidator(new BigDecimal("-"), new BigDecimal("")));
}
/* COLUMN NAME: PRODUCT_ID ; ALIAS NAME: PRODUCT_ID */
protected void initInsertValidatorProductId() {
//getRecordInsertValidator().addFieldValidator(OrderItemPO.ICOL_PRODUCT_ID, new NumberSizeFieldValidator(new BigDecimal("-"), new BigDecimal("")));
}
/* COLUMN NAME: QUANTITY ; ALIAS NAME: QUANTITY */
protected void initInsertValidatorQuantity() {
//getRecordInsertValidator().addFieldValidator(OrderItemPO.ICOL_QUANTITY, new NumberSizeFieldValidator(new BigDecimal("-"), new BigDecimal("")));
}
/* COLUMN NAME: STATE ; ALIAS NAME: STATE */
protected void initInsertValidatorState() {
getRecordInsertValidator().addFieldValidator(OrderItemPO.ICOL_STATE, new RequiredFieldValidator());
getRecordInsertValidator().addFieldValidator(OrderItemPO.ICOL_STATE, new StringSizeFieldValidator(0, 40));
}
/* COLUMN NAME: LAST_UPDATED ; ALIAS NAME: LAST_UPDATED */
protected void initInsertValidatorLastUpdated() {
}
/* COLUMN NAME: CREATION_DATE ; ALIAS NAME: CREATION_DATE */
protected void initInsertValidatorCreationDate() {
}
protected RecordValidator recordUpdateValidator = new RecordValidatorImpl(PERSISTENT, true);
protected void initUpdateValidator() {
/* COLUMN NAME: ORDER_ITEM_ID ; ALIAS NAME: ORDER_ITEM_ID */
initUpdateValidatorOrderItemId();
/* COLUMN NAME: ORDER_ID ; ALIAS NAME: ORDER_ID */
initUpdateValidatorOrderId();
/* COLUMN NAME: PRODUCT_ID ; ALIAS NAME: PRODUCT_ID */
initUpdateValidatorProductId();
/* COLUMN NAME: QUANTITY ; ALIAS NAME: QUANTITY */
initUpdateValidatorQuantity();
/* COLUMN NAME: STATE ; ALIAS NAME: STATE */
initUpdateValidatorState();
/* COLUMN NAME: LAST_UPDATED ; ALIAS NAME: LAST_UPDATED */
initUpdateValidatorLastUpdated();
/* COLUMN NAME: CREATION_DATE ; ALIAS NAME: CREATION_DATE */
initUpdateValidatorCreationDate();
}
/* COLUMN NAME: ORDER_ITEM_ID ; ALIAS NAME: ORDER_ITEM_ID */
protected void initUpdateValidatorOrderItemId() {
}
/* COLUMN NAME: ORDER_ID ; ALIAS NAME: ORDER_ID */
protected void initUpdateValidatorOrderId() {
getRecordUpdateValidator().addFieldValidator(OrderItemPO.ICOL_ORDER_ID, new NotNullFieldValidator());
}
/* COLUMN NAME: PRODUCT_ID ; ALIAS NAME: PRODUCT_ID */
protected void initUpdateValidatorProductId() {
}
/* COLUMN NAME: QUANTITY ; ALIAS NAME: QUANTITY */
protected void initUpdateValidatorQuantity() {
}
/* COLUMN NAME: STATE ; ALIAS NAME: STATE */
protected void initUpdateValidatorState() {
getRecordUpdateValidator().addFieldValidator(OrderItemPO.ICOL_STATE, new NotNullFieldValidator());
}
/* COLUMN NAME: LAST_UPDATED ; ALIAS NAME: LAST_UPDATED */
protected void initUpdateValidatorLastUpdated() {
}
/* COLUMN NAME: CREATION_DATE ; ALIAS NAME: CREATION_DATE */
protected void initUpdateValidatorCreationDate() {
}
protected RecordConvertor recordConvertor = new RecordConvertorImpl(PERSISTENT);
protected void initConvertor() {
/* COLUMN NAME: ORDER_ITEM_ID ; ALIAS NAME: ORDER_ITEM_ID */
initConvertorOrderItemId();
/* COLUMN NAME: ORDER_ID ; ALIAS NAME: ORDER_ID */
initConvertorOrderId();
/* COLUMN NAME: PRODUCT_ID ; ALIAS NAME: PRODUCT_ID */
initConvertorProductId();
/* COLUMN NAME: QUANTITY ; ALIAS NAME: QUANTITY */
initConvertorQuantity();
/* COLUMN NAME: STATE ; ALIAS NAME: STATE */
initConvertorState();
/* COLUMN NAME: LAST_UPDATED ; ALIAS NAME: LAST_UPDATED */
initConvertorLastUpdated();
/* COLUMN NAME: CREATION_DATE ; ALIAS NAME: CREATION_DATE */
initConvertorCreationDate();
}
/* COLUMN NAME: ORDER_ITEM_ID ; ALIAS NAME: ORDER_ITEM_ID */
protected void initConvertorOrderItemId() {
}
/* COLUMN NAME: ORDER_ID ; ALIAS NAME: ORDER_ID */
protected void initConvertorOrderId() {
}
/* COLUMN NAME: PRODUCT_ID ; ALIAS NAME: PRODUCT_ID */
protected void initConvertorProductId() {
}
/* COLUMN NAME: QUANTITY ; ALIAS NAME: QUANTITY */
protected void initConvertorQuantity() {
}
/* COLUMN NAME: STATE ; ALIAS NAME: STATE */
protected void initConvertorState() {
// getRecordConvertor().addFieldConvertor(OrderItemPO.ICOL_STATE, new TrimWhiteSpaceFieldConvertor());
// getRecordConvertor().addFieldConvertor(OrderItemPO.ICOL_STATE, new UpperCaseFieldConvertor());
}
/* COLUMN NAME: LAST_UPDATED ; ALIAS NAME: LAST_UPDATED */
protected void initConvertorLastUpdated() {
}
/* COLUMN NAME: CREATION_DATE ; ALIAS NAME: CREATION_DATE */
protected void initConvertorCreationDate() {
}
public OrderItemPoCtl(){
init();
}
public OrderItemPoCtl(Object [] parameters){
super(parameters);
}
protected void init() {
initInsertValidator();
initUpdateValidator();
initConvertor();
}
public void beforeInsert(PersistentObject persistentObject) {
try {
executeInsertRule(persistentObject);
} catch (RuntimeRuleException e) {
throw e;
} catch (RuleException e) {
throw new RuntimeRuleException(e);
} catch (Exception e) {
throw new RuntimeRuleException(e.getMessage());
}
}
public void executeInsertRule(PersistentObject persistentObject) throws Exception {
executeConvertorRule(persistentObject);
executeInsertValidatorRule(persistentObject);
}
public void beforeUpdate(PersistentObject persistentObject) {
try {
executeUpdateRule(persistentObject);
} catch (RuntimeRuleException e) {
throw e;
} catch (RuleException e) {
throw new RuntimeRuleException(e);
} catch (Exception e) {
throw new RuntimeRuleException(e.getMessage());
}
}
public void executeUpdateRule(PersistentObject persistentObject) throws Exception {
executeConvertorRule(persistentObject);
executeUpdateValidatorRule(persistentObject);
}
protected void executeConvertorRule(PersistentObject persistentObject) throws Exception {
getRecordConvertor().executeRule(persistentObject);
}
protected void executeInsertValidatorRule(PersistentObject persistentObject) throws Exception {
getRecordInsertValidator().executeRule(persistentObject);
}
protected void executeUpdateValidatorRule(PersistentObject persistentObject) throws Exception {
getRecordUpdateValidator().executeRule(persistentObject);
}
public FieldValidator getFieldValidator() {
return recordInsertValidator;
}
public FieldConvertor getFieldConvertor() {
return recordConvertor;
}
public PersistentObject getPersistentObject() {
return PERSISTENT;
}
protected RecordValidator getRecordInsertValidator() {
return recordInsertValidator;
}
protected RecordValidator getRecordUpdateValidator() {
return recordUpdateValidator;
}
protected RecordConvertor getRecordConvertor() {
return recordConvertor;
}
public Object clone() throws CloneNotSupportedException {
OrderItemPoCtl ctl = (OrderItemPoCtl) super.clone();
ctl.recordConvertor = (RecordConvertor) getRecordConvertor().clone();
ctl.recordInsertValidator = (RecordValidator) getRecordInsertValidator().clone();
ctl.recordUpdateValidator = (RecordValidator) getRecordUpdateValidator().clone();
return ctl;
}
}
They implement PersistentRule and LifeCycleController interfaces (see the API documentation) and can be used as parameters to Persistency.insert and Persistency.update methods as well as independently. They contain validations and conversions (commented out) generated out of the database metadata. You should never modify the generated classes. If you want to use them modified you should extend them and override the protected methods.
By design the generated classes contain instances of RecordValidator and RecordConvertor interfaces. Each of them, in turn, contain an array of field validators and field convertors, respectively, per every field. Thus, for each field a set of validations and conversions can be performed when PersistentRule.executeInsertRule(...) or PersistentRule.executeUpdateRule(...) is called. ODAL provides a set of predefined field validators that implement FieldValidator interface (see the API documentation). When the PersistentObject does not pass the validation RuleException is thrown. It internally contains an array of other RuleException instances that were thrown during the validation and can be retrieved with getElementExceptions() method. These exceptions are collected from all the partial field validations. Once an exception for a particular field is thrown it gets added to the RuleException array, further validation for this field gets interrupted and gets performed for the next field.
Occasionally, you will find a need to have an object that can accept result of query that does not match any particular table or set of tables in a database. Moreover, since these are ad-hoc queries their structure may frequently change. One way to do it is to use a generic PersistentObject as a container. ODAL, however, offers a way to generate strictly typed Bean objects out of ad-hoc queries.
To do that you have to create a query factory implementing BasicManagedQueryFactory interface. A sample implementation is given below,
public class AdHocQueryFactory implements BasicManagedQueryFactory {
private QueryFactory delegate;
public AdHocQueryFactory() {
}
public Class getDelegateType() {
return SupportedDelegates.QUERY_FACTORY;
}
public void setDelegate(QueryFactoryBase delegate) {
this.delegate = (QueryFactory) delegate;
}
public BasicQuery newBasicQuery() {
String sql = Query.SELECT + "'SOME_VALUE'" + Query.FROM +
Anonymous.TABLE_ANONYMOUS;
Query query = delegate.newQuery(sql);
query.setName("AD_HOC_OBJECT");
query.addToWhere(Anonymous.COL_ID).addToWhere("=?");
return query;
}
public BasicQuery newBasicQuery(String sql) {
return null;
}
public void setDefaultParameters(Parameter[] parameters) {
}
}
Most importantly, you have to implement newBasicQuery() method and set query name since it is used to derive the generated object name. The query factory then can be used in your application to retrieve the generated objects.
Create a configuration file (let's call it query-config.sdl) for you query generator,
{
QUERY_01 = {
className = AdHocQueryFactory
defaultParameters = [ { value = 1 } ]
}
}
Create a copy of your $CONFIG/persistent-descriptor-config.properties file, rename it to, say, query-descriptor-config.properties. Modify its internal_desc_file, external_desc_file values to make them different from the default ones and add the following entry,
query_desc_file=path/query-config.sdl
Alternatively, we could avoid writing a query factory by modifying the query-config.sdl like this,
QUERY_01 = {
className = NULL
aliases = ["AD_HOC_OBJECT"]
sql = "select 'SOME_VALUE' from ANONYMOUS where ID=?"
defaultParameters = [ { value = 1 } ]
}
in which case the SQL statement is stored directly in the configuration file.
Run
$ODAL_HOME/bin/desc-po.sh $CONFIG/query-descriptor-config.properties
to generate the descriptors.
Create a copy of $CONFIG/persistent-object-config.sdl file from, rename it to, say, query-object-config.sdl. Modify its intern_path and extern_path entries to point to the generated descriptors.
Run
$ODAL_HOME/bin/po.sh $CONFIG/query-object-config.sdl
to generate the persistent objects.
ODAL provides Call API that is very similar to the Query one to handle stored procedures. Calls are passed to Persistency for execution.
Executing calls that do not return result sets is done with Persistency.executeCall(...) method as it is shown in the example below,
Call call = persistency.getCallFactory().newCall();
call.setSql("{ call sp_upgrade_account( ? ) }");
call.addInParameter(ColumnType.LONG, new Long(111));
The call executes stored procedure sp_upgrade_account that takes one IN type parameter of long type.
More interesting though are cases returning result sets. ODAL supports calls returning result sets of two types: through reference cursor parameters or plain ones. Depending on type of database you choose the method of result set retrieval. Multiple retrieved result sets are also supported. In the example below, it is demonstrated how to retrieve multiple result sets through reference cursor mechanism (which is appropriate for Oracle or Postgres databases). We assume that sp_get_cust_orders stored procedure returns customers together with their orders as 2 result sets,
MultiRsPersistentObjectFactoryImpl objectFactory = new MultiRsPersistentObjectFactoryImpl(
new PersistentObject []{new CustomerPO(), new OrderPO()}
);
Call call = persistency.getCallFactory().newCall(objectFactory);
call.setSql("{ call sp_get_cust_orders( ?, ?, ? ) }");
call.addInParameter(ColumnType.LONG, ORDER_ID);
call.addRefCursorParameter();
call.addRefCursorParameter();
MultipartCollection multipart = persistency.selectMultiPartResultCall(call);
Collection customers = multipart.get(0);
Collection orders = multipart.get(1);
We created an instance of MultiRsPersistentObjectFactory and used it as a single result factory when instantiating the Call. We also assume that CustomerPO and OrderPO are basic persistent objects. Composites are not currently supported with Calls.
In the last example of the previous paragraph we assumed that we have already basic of CustomerPO and OrderPO types that can receive the retrieved data. But what if the objects returned by the result sets do not correspond to any particular table? ODAL provides the way to actually generate basic of Bean type from stored procedure calls, even returning multiple result sets. It is done similarly to generating from ad-hoc queries.
The first way to do it is through creating a call factory implementing BasicManagedQueryFactory interface. A sample implementation is given below,
public class CustomCallFactory implements BasicManagedQueryFactory {
private CallFactory delegate;
public Class getDelegateType() {
return SupportedDelegates.CALL_FACTORY;
}
public void setDelegate(QueryFactoryBase delegate) {
BasicManagedQueryFactory.SupportedDelegates.validate(delegate.getClass());
this.delegate = (CallFactory) delegate;
}
public void setDefaultParameters(Parameter[] parameters) {
}
public BasicQuery newBasicQuery() {
Call call = delegate.newCall(new AliasTestMaster());
call.setSql("{ call sp_get_cust_orders( ?, ?, ? ) }");
call.setName("CALL");
return call;
}
}
Create a configuration file (let's call it call-config.sdl) for you query generator,
{
CALL_MULTI = {
className = CustomCallFactory
aliases = ["CALL_CUSTOMER" "CALL_ORDER"]
# sql = "{ call sp_get_cust_orders( ?, ?, ? ) }"
defaultParameters = [
{ value = 111
columnType = "LONG"
mode = "IN"
}
{ refCursor = TRUE }
{ refCursor = TRUE }
]
}
}
Note that since we expect the call to bring multiple result sets (2 in this case) we defined 2 aliases "CALL_CUSTOMER" and "CALL_ORDER" which will be used to derive generated classes names according to Java convention. In this case the call name will be ignored.
The 2nd way to achieve the same result is by commenting out the className and uncommenting the sql entry in the configuration file above.
The rest of the steps is not different from generating from ad-hoc queries.
ODAL provides caching infrastructure to facilitate working with ODAL and transactions. ODAL caching infrastructure is based on OdalCache interface. It is very simple one containing only five methods: put, get, remove, clear and getName. ODAL also provides one workable implementation of it – ExpiringLruCache (see the API documentation).
Once you implemented the OdalCache interface you can integrate the cache with ODAL. You do it through the provided cache factories. A code snippet below shows initialization of the Persistency CacheFactoryManager
DefaultPersistencyAdapter persistency = new DefaultPersistencyAdapter("configPath");
OdalCacheConfig config = new OdalCacheConfig();
config.setTransactionSensitive(Boolean.TRUE);
//
// If key factory is not passed as a parameter to registerCache method then object's default // one is used: for PersistentObject the one defined by its toKey() method, for query it is // derived from its name/SQL and its parameters. Each cache can be configured individually // by passing OdalCacheConfig while registering.
//
persistency.getCacheFactoryManager().registerCache(new ExpiringLruCache("BY_ID"), config);
Upon registering with CacheFactoryManager the the core cache instance gets wrapped in another class type of which depends on the factory settings. In the example above we set it to be transaction sensitive meaning that the registered cache will implement OdalTransactionSensitiveCache (see the API) and hence it can be added to a transaction as a listener and its removed entries get actually removed from the cache once the transaction is committed. This feature is especially important for distributed caches to provide consistent view across all the application instances.
By default the cached are cloned and flattened before caching and cloned and unflattened after.
Multi-index cache factory lets you to access the cached object by different keys. For example, you cache your object by ID but in the application you want to access it by ID or by NAME, assuming that its name uniquely identifies the object. ODAL provides this ability though its PersistencyMultiIndexCacheFactoryImpl factory. A code sample below shows how to initialize the PersistencyMultiIndexCacheFactoryImpl factory and register it with CacheFactoryManager,
DefaultPersistencyAdapter persistency = new DefaultPersistencyAdapter("configPath");
PersistencyMultiIndexCacheFactoryImpl persistencyCacheFactory = new PersistencyMultiIndexCacheFactoryImpl();
persistencyCacheFactory.setTransactionSensitive(true);
persistencyCacheFactory.registerCache(new ExpiringLruCache(“BY_ID”), new PoKeyFactory());
persistencyCacheFactory.registerCache(new ExpiringLruCache(“BY_NAME”), new PoSimpleKeyFactory(new int[]{Person.ICOL_NAME}));
OdalKeyedCache byIdCache = persistencyCacheFactory.getCache(“BY_ID”);
OdalKeyedCache byNameCache = persistencyCacheFactory.getCache(“BY_NAME”);
PersistencyMultiIndexCacheFactoryImpl persistencyCacheFactory = new PersistencyMultiIndexCacheFactoryImpl();
persistencyCacheFactory.setTransactionSensitive(true);
persistencyCacheFactory.registerCache(new ExpiringLruCache(“BY_ID”), new PoKeyFactory());
persistencyCacheFactory.registerCache(new ExpiringLruCache(“BY_NAME”), new PoSimpleKeyFactory(new int[]{Person.ICOL_NAME}));
OdalKeyedCache byIdCache = persistencyCacheFactory.getCache(“BY_ID”);
OdalKeyedCache byNameCache = persistencyCacheFactory.getCache(“BY_NAME”);/
Note that when registering, we passed the second parameter – the key factory that defines how to create a key out of the object entry. The caches returned from the factory upon registering are instances of the OdalKeyedCache, cache that is aware of its key factory. You can use the multi-index cache independently as follows,
Person person = new Person(ID);
person.setName(“John Smith”);
byIdCache.put( person );
....
// Now the value we get is from cache:
person = byNameCache.get( byNameCache.getKeyFactory(person) );
// Remove it:
byNameCache.remove(byNameCache.getKeyFactory(person) );
// This returns null:
Object value = byNameCache.get( byNameCache.getKeyFactory(person) );
// This returns null also
value = byIdCache.get( byIdCache.getKeyFactory(person) );
Once the cache is registered with one of the ODAL cache factories, ODAL can optionally cache/retrieve from cache. To make it do so, set the desirable cache to use in the LifeCycleController that is passed to Persistency.load or Persistency.selectXXX methods. Methods that return single instance of persistent object (Persistency.load or Persistency.selectFirst) by example persistent object, will also cache that single object and retrieve it if it is found. Persistency.update and Persistency.delete methods will remove it from cache. In the example below it is shown how to integrate multi-index cache with Persistency.
DefaultPersistencyAdapter persistency = new DefaultPersistencyAdapter("configPath");
//
// Initialize MultiIndexCacheFactoryImpl
//
PersistencyMultiIndexCacheFactoryImpl multiIndexCacheFactory = new PersistencyMultiIndexCacheFactoryImpl();
multiIndexCacheFactory.setTransactionSensitive(true);
multiIndexCacheFactory.registerCache(new ExpiringLruCache("BY_ID"), new PoKeyFactory());
multiIndexCacheFactory.registerCache(new ExpiringLruCache("BY_NAME"),
new PoSimpleKeyFactory(new int[]{Person.ICOL_NAME}));
persistency.getCacheFactoryManager().registerCacheFactory(multiIndexCacheFactory);
Transaction transaction = persistency.getTransactionManager().begin();
//
// After the load by id the object gets into both byIdCache and byNameCache
//
BasicLifeCycleController byIdController = new BasicLifeCycleController("BY_ID");
Person person = (Person) persistency.load(new Person(JOHN_SMITH_ID), byIdController);
System.out.println(person);
// Let's assume that the person is found - then it is also cached
//
// Now let's select by name - and let us assume its Person with name "John Smith"
// has id JOHN_SMITH_ID
//
Person queryObject = new Person();
queryObject.setName("John Smith");
person = (Person) persistency.selectFirst(queryObject, new BasicLifeCycleController("BY_NAME"));
// Since the object is cached with the 1st query and we are using multi-index
// cache the object that is selected with selectFirst is the one from the
// cache and it is the one with id JOHN_SMITH_ID
//
// Now we modify the value:
//
person.setDescription("bogus");
persistency.update(person, byIdController);
//
// After update - "Person" is not yet removed from byIdCache and byNameCache caches:
//
persistency.getTransactionManager().commit(transaction);
//
// After commit - "Person" gets actually deleted from the cache again since the caches
// we use are transaction sensitive
//
Cached objects are actually complete object trees – ODAL does not get every node by its id from cache.
ODAL also provides mechanism to cache query results. It is done in the manner very much similar to that for singular persistent objects. However there are few differences:
Removing results from query caches is done independently of Persistency.
The custom key factory must be the one that can produce key out of Query object instead of AbstractPersistentObject.
Below is an example of using query cache with ODAL,
DefaultPersistencyAdapter persistency = new DefaultPersistencyAdapter("configPath");
OdalCache queryCache = new ExpiringLruCache("QUERY_CACHE");
persistency.getCacheFactoryManager().registerCache(queryCache);
// .............
//
// Make query:
//
Person queryObject = new Person();
queryObject.setCategory("Temporary Worker");
Query query = persistency.getQueryFactory().newQueryByExample(queryObject);
query.setName("QUERY_TEMP_WORKER");
// Retrieve and cache:
BasicLifeCycleController controller = new BasicLifeCycleController("QUERY_CACHE");
Collection collection = persistency.select(query, controller);
Result collection is cached now and the 2nd call with the same query will retrieve the result from the cache. Note that when registering the query cache we used BasicQueryKeyFactory as a key factory. It uses query name and set of parameters to produce as a key. So totally different queries with the same name may conflict. If query is not given a name then SQL statement and set of query parameters is used instead.
Imaging a situation when you have a User object that has a password and email fields that should not be retrieved for certain types of requests. Let us also say that in some situations you have to retrieve User with email and without password in another with password but without email. To return all those types of data with ODAL we have several options. 1st one is to use query without setting persistent object factory, in which case the projection data will be returned in generic PersistentObject types. But if we still want the data to be Java Beans we can also generate new type of object out of the query. In many cases it is not an option or not a good option since it will create a bunch of almost identical objects that have to named and maintained. ODAL has a feature that allows you to retrieve data into an object without populating all its fields.
It is done by setting column filters on the query object like in the following example,
String [] excluded = new String [] {User.COL_PASSWORD, User.COL_EMAIL};
query = queryFactory.newQuery(sql);
query.columnFilters().addExcludeEntryFilter(excluded, false);
query.setSingularResultFactory(new User());
Transaction transaction = transactionManager.begin();
Collection collection = persistency.select(query);
transactionManager.commit(transaction);
where the query will retrieve all the Users from the database with no email or password columns populated.
Some projects or their parts are about just loading data into the database and sometimes its amounts of this data are large. If you look at Persistency interface hierarchy you can notice that one its parents is InsertPersistency. It is created specifically for such kind of jobs. ODAL provides and alternative implementation of this interface – SqlLoaderPersistencyImpl – that saves data in Oracle SQL Loader format. It can be used interchangeably with any implementation of Persistency interface that saves data directly to the database. This example demonstrates technique how to create a specialized persistence as a plug-in to the application.
ODAL uses its own logger interface com.completex.objective.components.log.Log. It also provides primitive implementations of it: StdErrorLogAdapter, StdOutputLogAdapter and null logger Log.NULL_LOGGER. These are not the loggers we would recommend for real application though.
ODAL also provides an adapter for org.apache.commons.logging.Log logger. You can use it or you can create your own implementation of ODAL Log as a wrapper to the logger of your choice.
Once you have an instance of com.completex.objective.components.log.Log interface you should set the logger on DefaultPersistencyFactory and DefaultTransactionManagerFactory instances with setLogger(Log log) method before using the corresponding factory methods.
If you decided that you need your DOs to be POJO Beans then you need to employ Model 2 approach. To minimize maintenance it is recommended to generate your POJOs the same way you generate the POs. The DOs will be descendants of the generated ones or the generated ones themselves.
ODAL allows you to generate your DOs which will reflect the structure of the generated POs. The generation tool will also generate the default mapper between PO and DO classes. For a given mapper, one-to-one correspondence between DO and PO classes must exist.
MappingPersistency interface that has to be used when employing the Model 2 approach is similar to Persistency one.
As far as select queries are concerned both of them extend SelectPersistency interface. You would use Query interface or PersistentObject to specify the query and receive corresponding DO or collection of DOs the query persistent objects are mapped to. If the mapping is not found then POs are returned instead. Returned DOs are real POJOs meaning that they are not proxies of the generated or defined objects and do not need any type of annotations. That is why on that level lazy loading does not exist. Let's say you have a DO Customer that contains an instance of Contact and they are mapped to POs CpxCustomerPO and ContactPO, respectively, and CpxCustomerPO is defined to lazily load ContactPO then the query to load Customer together with its Contact objects will look like,
/**
* Load all the customers. Utilizes BasicLifeCycleController.convertAfterRetrieve method
* to pre-load otherwise lazily loadable Contact.
*
* @return list of customers
* @throws CustomerException
*/
public List loadAllCustomers() throws CustomerException {
try {
return (List) persistency.select(new CpxCustomerPO(), new BasicLifeCycleController() {
public Object convertAfterRetrieve(AbstractPersistentObject persistentObject) {
((CpxCustomerPO) persistentObject).getContact();
return persistentObject;
}
});
} catch (OdalPersistencyException e) {
throw new CustomerException(e);
}
}
where the controller is used to call the getter on the CpxCustomerPO object to retrieve the ContactPO. Both of them get converted to corresponding DOs which will have both Customer and Contact populated. All the lazy associations to be populated have to be loaded within query context.
Both of these operations are simple and similar to those performed with Persistency interface. Delete is done by primary key. Both insert and delete methods will throw an exception if the mapping is not found, unless the inserted/deleted object is already an instance of PersistentObject.
Update is the most complex of all the CRUD operations and should be explained in details. There are 2 main scenarios for update. The 1st one is where the object is being updated in the same session where it was loaded (selected). The 2nd when the update and the load happen in different sessions.
Let's consider the 1st scenario. When the object gets loaded, the object itself and the corresponding PO it is mapped to get stored in the ThreadSession object. On update, the Bean is not an instance of PO then the corresponding PO is found in the session, it gets updated from the Bean and saved in the database. Update method returns the same instance of the Bean being passed as the parameter.
With the 2nd scenario, if Bean is not instance of PO then the load is performed the returned PO is then merged with the incoming one (that is produced by converting the Bean into PO) and the differences are then stored in the database. You should use controller to force (with corresponding getters) retrieval of all necessary lazily loaded fields. The method returns a new instance of the Bean in this case.
ThreadSession object is based on ThreadLocal and accumulates references to the object entries. By default the session gets cleaned on transaction release – when one of TransactionManager.commit(Transaction) or TransactionManager.rollback(Transaction) methods is called. You can also use ThreadSession.clear() method to clear session earlier if you deem it appropriate.
You can further reduce the footprint by setting DatabaseMappingPersistencyImpl.cacheQueriesInSession to false. In this case only the results of the methods that return one object (load and selectFirst) will be stored in ThreadSession.
If you need to populate some flat Bean (or array of them) as a result of query, then you can do it using AdHocPoMappingHandler. Below is the example that populates Order Bean through the ad-hoc query mechanism,
Object bean =
mappingPersistency.load(new OrderPO(ID), new BasicLifeCycleController() {
public Object convertAfterRetrieve(AbstractPersistentObject persistentObject) {
return mappingPersistency.getAdHocPoMappingHandler().convert((PersistentObject) persistentObject, Order.class);
}
});
Default AdHocPoMappingHandler is reflection based and it matches PO Record column names to corresponding Bean fields. Also by default it is using name extrapolation and can match NAME_ONE, for instance, to nameOne Java name.
If you use ad-hoc query tree to retrieve tree of results ODAL will try to populate the POJO tree once provided the type map – see AdHocPoMappingHandler.convert(PersistentObject po, Class beanClass, Map typeMap) method. If the column or link name is not found in the type map it will use the default mapper provided by the MappingPersistency to find the mapping.
Default Mapper implementation which is provided by ODAL is DynamicMapperImpl and it is based on Java reflection API. Since PO trees can only contain collections of another POs, it only maps POs trees to Bean trees that only contain collections of other Beans. You can also provide custom value mapper (MappingHandler – see the API) for a specific value path. Value path is defined as <class name>#<value path pattern>. Value path pattern is a regular expression that will be matched to a field path. The field path is a string of field name separated by period. Indexed fields at certain index can be referred as <field name>[index]. For instance, "com.impl.Bean#fileds\\[(\\d+)\\].childBean" will match "com.impl.Bean#fileds[1].childBean".
The table below describes the set of code generating commands provided by ODAL. The scripts reside under $ODAL_HOME/bin directory. The table also gives the name of a corresponding configuration file template (or templates) that can be found in $ODAL_HOME/config/ref directory.
Command | Description | Configuration Templates |
desc-po | Generates basic persistent object descriptors from database | persistent-descriptor-config.properties |
po | Generates basic persistent objects | persistent-object-config.sdl |
po-cmp | Generates composite persistent objects | composite-po-config.sdl |
desc-qry | Generates basic persistent object descriptors from ad-hoc queries or stored procedure calls | query-descriptor-config.sdl or call-descriptor-config.sdl |
bean | Generates POJO Beans - base for Domain Objects | bean-config.sdl (see reference) |
All the code generators accept now the 2nd parameter – env.properties file, containing token/value pairs to resolve configuration file placeholder tokens – expressions of ${token} kind. For example, in the configuration file you can have expression key = ${token}, and in the env.properties file – token = /dev. When the configuration file gets processed its ${token} value gets replaced with /dev.
ODAL provides SQL command line tool that can execute any SQL command or run a script against a database that has a JDBC driver. The command is sql-cmd. Run it without arguments to get help.
The distribution comes with set of examples that can be found in $ODAL_HOME/examples directory. Also there is more comprehensive ODAL Pet Store application samples that can be found in $ODAL_HOME/odal-petstore.tgz f (Model 1) and $ODAL_HOME/odal-petstore2.tgz (Model 2) files. To run the samples you have to untar them it and follow the instructions of the corresponding README.txt files.
Install Terracotta under $TERRA_HOME from http://www.terracotta.org/.
Copy ODAL cluster module into terracotta repository:
cp $ODAL_HOME/integration/tc/clustered-odal-1.0.0.jar $TERRA_HOME/modules/org/terracotta/modules
Configure/register caches that you want to cluster as “singleton” ones. If you do it through the SDL file supplied to a DefaultPersistencyAdapter then your configuration file should look like:
####################################
# Persistency Properties
####################################
{
driver="org.hsqldb.jdbcDriver"
url="jdbc:hsqldb:file:data/petstore"
user=sa
password=""
cacheFactory = {
global = {
disabled = FALSE
}
caches = {
categoryCache = {
class = com.completex.objective.components.ocache.impl.ExpiringLruCache
transactionSensitive = TRUE
# Set it to TRUE for Terracotta cache sample
singleton = TRUE
maxSize = 100
cacheFlushInterval = "24:00:00.000"
entryFlushInterval = "24:00:00.000"
disabled = FALSE
}
.....
}
}
}
Create tc-config.xml file which will look like
<tc:tc-config xmlns:tc="http://www.terracotta.org/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.terracotta.org/schema/terracotta-4.xsd">
<!--http://svn.terracotta.org/svn/forge/cookbook/instrumentation/tc-config.xml-->
.....
<clients>
<modules>
<module name="clustered-odal" version="1.0.0" group-id="org.terracotta.modules"/>
</modules>
</clients>
<application>
<dso>
<instrumented-classes>
<include>
<class-expression>com.odal.petstore.persistence.gen.*.*</class-expression>
</include>
<include>
<class-expression>com.odal.petstore.domain.*</class-expression>
</include>
</instrumented-classes>
</dso>
</application>
</tc:tc-config>
where <instrumented-classes> section will contain you persistent objects and their descendants.
Start terracotta server with created tc-config.xml.
Both Pet Store examples can be launched with clustered caches.
ODAL integration with Terracotta is quite easy since ODAL generated classes do not use proxies or other byte code manipulations.
There are several ways ODAL can be initialized with Spring Framework (http://static.springframework.org/). Example below shows one of the simplest configurations. Spring configuration file spring.xml:
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" "http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<bean id="odalBean" class="com.spring.odal.OdalBean">
<property name="properties">
<props>
<prop key="sdl">
<![CDATA[
{
driver="org.hsqldb.jdbcDriver"
url="jdbc:hsqldb:file:data/petstore"
user=sa
password=""
cacheFactory = {
global = {
disabled = FALSE
}
caches = {
categoryCache = {
class = com.completex.objective.components.ocache.impl.ExpiringLruCache
transactionSensitive = TRUE
# Set it to TRUE for Terracotta cache sample
# singleton = TRUE
maxSize = 100
cacheFlushInterval = "24:00:00.000"
entryFlushInterval = "24:00:00.000"
disabled = FALSE
}
productCache = {
class = com.completex.objective.components.ocache.impl.ExpiringLruCache
transactionSensitive = TRUE
# Set it to TRUE for Terracotta cache sample
# singleton = TRUE
maxSize = 100
cacheFlushInterval = "24:00:00.000"
entryFlushInterval = "24:00:00.000"
disabled = FALSE
}
}
}
}
]]>
</prop>
</props>
</property>
</bean>
</beans>
ODAL bean class:
package com.spring.odal;
import org.springframework.beans.factory.BeanNameAware;
import org.springframework.beans.factory.DisposableBean;
import org.apache.commons.logging.LogFactory;
import com.completex.objective.components.persistency.core.adapter.DefaultPersistencyAdapter;
import com.completex.objective.components.persistency.Persistency;
import com.completex.objective.components.log.adapter.LoggingLogImpl;
import com.completex.objective.components.log.Log;
import java.util.Properties;
import java.io.IOException;
/**
* @author Gennady Krizhevsky
*/
public class OdalBean implements DisposableBean, BeanNameAware {
private static final Log logger = new LoggingLogImpl(LogFactory.getLog(OdalBean.class));
private Persistency persistency;
private String beanName;
private Properties properties;
public void initialize() {
if (persistency == null) {
try {
String sdl = properties.getProperty("sdl");
persistency = DefaultPersistencyAdapter.newPersistencyAdapterBySdlString(sdl, logger);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
public void destroy() throws Exception {
if (persistency != null) {
persistency.shutdown();
}
}
public Properties getProperties() {
return properties;
}
public void setProperties(Properties properties) {
this.properties = properties;
}
public Persistency getPersistency() {
return persistency;
}
public void setBeanName(String beanName) {
this.beanName = beanName;
}
public String getBeanName() {
return beanName;
}
}
ODAL bean example application:
package com.spring.odal;
import com.completex.objective.components.persistency.Persistency;
import org.apache.log4j.xml.DOMConfigurator;
import org.springframework.beans.factory.BeanFactory;
import org.springframework.beans.factory.xml.XmlBeanFactory;
import org.springframework.core.io.FileSystemResource;
public class OdalBeanExample {
public static void main(String[] args) {
DOMConfigurator.configureAndWatch("config/logger.xml", 5 * 1000);
BeanFactory factory = new XmlBeanFactory(new FileSystemResource(
"config/spring.xml"));
OdalBean odalBean = (OdalBean) factory.getBean("odalBean");
odalBean.initialize();
Persistency persistency = odalBean.getPersistency();
System.out.println("persistency = " + persistency);
}
}